
출처 :
https://www.youtube.com/watch?v=nDPWywWRIRo&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk&index=12
http://cs231n.stanford.edu/schedule.html

컴퓨터 비전 태스크는 다양하게 존재하고, 그 중 가장 코어하고 전통적인 태스크는 분류일 것이다.
위 강의에서는 이 외의 다양한 task에 대해서 알아보고자 한다.
목차는 다음과 같다.
1. Semantic Segmentation
2. Object Detection
3. Instance Segmentation
4. Beyond 2D Object Detection...
이 글에서는 각 task를 수행하기 위한 방법들, 모델에 대한 개괄을 정리한다.
1. Semantic Segmentaion
[ Semantic segmentation 문제(task)에 대하여 ]

기존 분류 문제처럼 각 이미지마다 어떤 라벨인지 분류하는 것이 아니라,
한 장의 이미지의 모든 각각의 픽셀에 대하여 카테고리 라벨링을 하는 것이다.
[ Semantic segmentation Idea (1) : Sliding Window ]
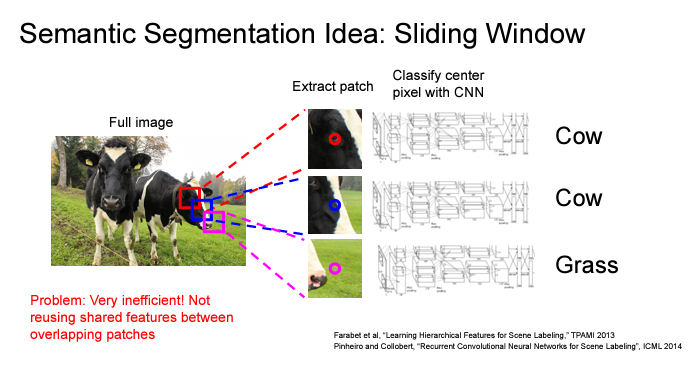
이미지를 크롭해서 각 크롭된 이미지별로 Convolutional Neural Network를 통과시켜서 중앙에 위치한 픽셀이 어떤 것을 나타내고 있는지 분류하는 작업니다. 하지만, 이 각 픽셀 당 이미지를 크롭하려면 당연히 엄청난 양의 연산이 필요하며, 바로이웃하는 픽셀의 경우 재사용될 리소스가 많음에도 불구하고 재사용을 하지 않으므로 상당히 비효율적이다.
[ Semantic segmentation Idea (2) : Fully Convolutional Network ]
그렇다면 conv layer를 이용해보자. 그런데 conv layer를 통과하면 통과할수록 그 사이즈가 작아지지 않나..? semantic segmantation의 결과는 input size와 output size가 같아야한단 말이다!
그래서 만약 segmentation을 c개로 한다면 3*H*W짜리 Input이 여러 개의 conv 레이어들을 거쳤을 때 그대로 c*H*W가 되도록 만들면 된다.
마지막에 각 픽셀별로 c개의 숫자가 나오면 argmax를 취해서 segmentation이 가능해지는 것이다.
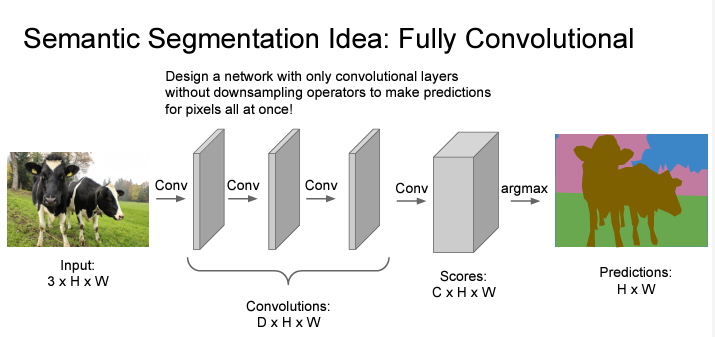
그런데 위와 같은 Fully Convolutional layer를 적용하면 생기는 문제점이 무엇일까?
input의 high resolution을 연산하는데 weight 연산량이 엄청 크다는 것이다.
이를 해결하기 위해서 Downsampling & Upsampling 과정을 거친다. 먼저, 이미지(input)의 full spatial resolution에 대하여 convolution 연산을 하지 않고, max-pooling이나 strided conv를 이용하여 피쳐맵을 down-sampling을 해준다. 그 다음에 기존에 convolution network에서 fc 레이어를 거치던 것과는 다르게 다시 upsampling을 해줘서 기존의 high-resolution으로 되돌려준다.
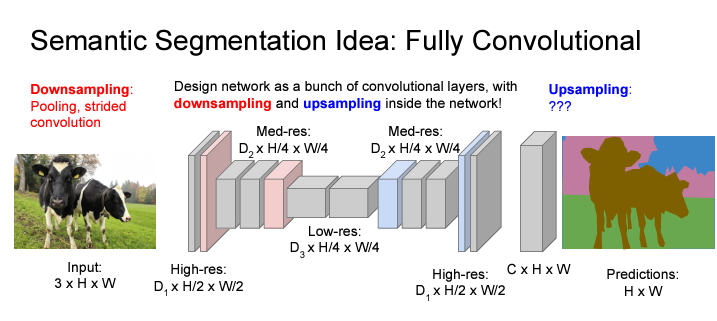
Downsampling은 convolutional network에서 하던대로 하면 되는데, upsampling은?
여러 가지 방법이 있다. 'Nearest Neighbor'와 'Bed of Nails'는 그림 그대로 쉽게 이해할 수 있고 'Max Unpooling'만 조금 설명을 덧붙이자면 downsampling 단계에서 max pooling한 위치를 그대로 upsampling 단계에서 max unpooling하는 것이다.


위의 upsampling 방식들은 learnable parameter가 없다. 즉, 그냥 함수이지 학습되는 layer가 아니라는 것이다.
Learnable upsampling 방식으로는 'Transpose Convolution'이 있다.
-> upsample the feature map + learn weights about how it wants to do that upsampling

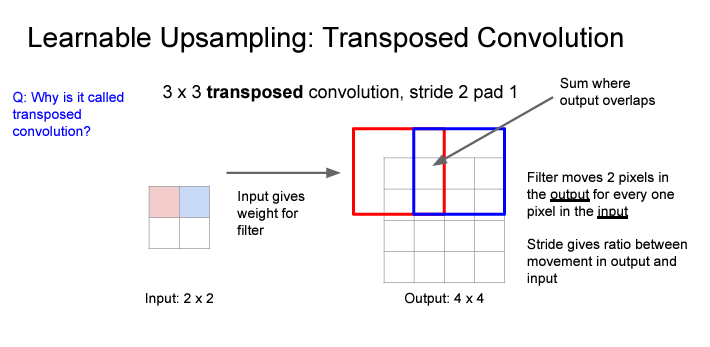

그렇다면 왜, "Transposed Convolution"이라고 부르는 것이람??

2. Object Detection
object detection 태스크는 이미지 및 비디오에서 유의미한 특징 객체를 탐지하는 작업이다.
객체를 탐지한다는 것은, 1. 객체가 무엇인지 분류하는 것 (classification) + 2. 분류된 객체가 어디 있는지 bounding box를 통해 위치를 파악하는 것 (localization) 을 통한 태스크인 것이다.
object detection은 탐지하는 object의 수에 따라 1. single-object detection 과 2. multi-object detection으로 나뉜다.
단 하나의 object에 대한 detection을 한다고 생각해보자.
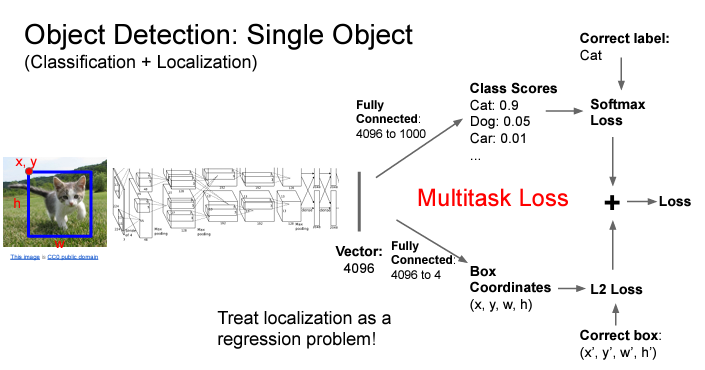
물체가 무엇인지 분류하는 전통적인 분류 문제 + 해당 물체가 어디있는지 그 좌표를 계산하는 회귀 문제, 두 가지 task에 대한 loss를 weighted sum으로 구하여 문제를 풀 수 있다.
[ Object Detection as Classification : Sliding Window ]
이제 여러 개의 object에 대한 detection을 수행하는 과제가 있다고 생각해본다.
semantic segmentation에서 봤었던 sliding window를 비슷하게 적용한다. 하나의 이미지를 여러 개의 crop으로 나누고, 각각의 다른 crop에 대해서 CNN을 적용해서 분류 작업을 수행한다.
그런데 bruteforce sliding window approach를 통해서는 crop을 이미지의 여러 위치에, 스케일을 다르게 해서 하나하나 다 적용해서 계산하려면 연산 비용이 많이 들 것이라고 예상할 수 있다.


따라서 crop할 region을 제안하는, "Region Proposal" : selective search 방법이 제안되었고 (딥러닝 방식이 아닌, 전통적인 cv 방식) 특정 객체가 포함되는 것으로 보이는 region에 한해서 classification이 진행된다.
여기서, object detector는 두 가지로 나뉜다. 1-stage Detector와 2-stage Detector가 있다.
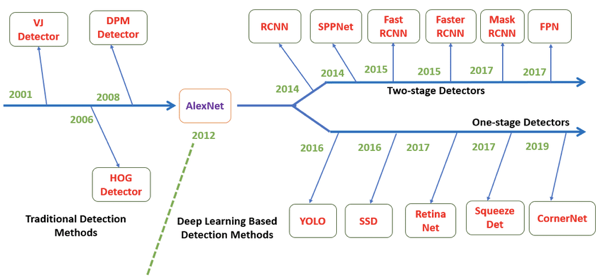
위 그림에서 아랫줄은 1-stage Detector를, 윗줄은 2-stage Detector의 모델들이다. 2-stage detector로는 대표적으로 R-CNN, Faster R-CNN, Mask R-CNN이 있고 얘네는 (1) region proprosal network를 이용해서 탐지할 region을 먼저 생성하고 (2) 그 region proposals들을 object classification + bounding-box regression 파이프라인으로 보낸다. 이런 2-stage 모델들은 높은 정확도를 보이지만 느리다는 단점이 있다.
1-stage 의 경우 대표적으로 YOLO와 SSD가 있는데, 얘네는 입력 이미지로 regression 문제로 분류 class 확률과 bouding box coordinates를 학습한다. 얘네는 정확도가 조금 낮지만 빠른 추론 속도를 보인다.
[ R-CNN ]
위 방법을 이용해서 등장(2013.11)한 R-CNN이다. R-CNN:Regions with CNN features은 제목이 말하는 바 그대로 region proposals를 CNN과 합치는 방법이다. CNN을 Object Detection 태스크에 최초로 적용시킨 모델이고 CNN을 이용한 검출 방식이 Classification 뿐만 아닌 Object Detection 분야에도 높은 수준의 성능을 낼 수 있다는 것을 보여준 의미 있는 2-stage detector 모델이다.
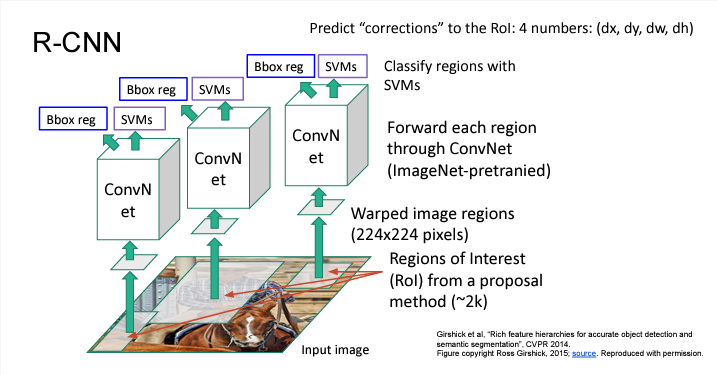
지금은 논문 리뷰 글이 아니니, 간단히 설명하면
1. Region Proposal network를 통해서 Region of Interest (RoI)를 약 2000개 구한다. (참고로 여기서 region proposal은 학습되는게 아님)
2. RoI는 사이즈가 모두 다를 것이니, 하나의 input 사이즈로 통일해준다.
3. ImageNet으로 사전훈련된 ConvNet을 통과시킨다.
4. SVM을 통해 각 crop region에 대한 classification을 수행한다.
5. Bounding Box 좌표에 대한 correction/offset (dx,dy,dw,dh)를 구하기 위한 regression을 수행한다.
R-CNN의 문제

- 2000개의 개별 이미지마다 다 저렇게 훈련시키다 보니 훈련과정도 오래 걸리고 메모리도 많이 필요하고
- 그렇게 다 훈련을 시켰다고 해도 inference가 느림
[ Fast R-CNN ]
그래서, Fast R-CNN은 각각의 RoI를 개별로 processing하는 대신에
input image 전체를 convolutional layers에 한 번에 집어넣는 방법을 이용한다.
ConvNet을 한 번에 통과시킨 다음에 proposal method로부터 얻은 RoI를 conv layer를 통과한 feature map에서 crop하는 것이다.
그 다음에, FC layer를 통과시키기 위해서 reshaping 과정을 거친다. "RoI Pooling" layer를 이용하여 이미지의 크기를 맞춰주고 최종적으로 cully-connected layer를 통과시켜 분류를 시킨다.

아래의 network 별 consumed training-time & inference time을 살펴보면 Fast R-CNN이 훨씬 시간이 짧은데 Region Proposal 시간을 제외하고 보면 떠 짧아질 수 있음에도 불구하고 Region proposals에 2초나 까먹고 있다는 사실을 확인할 수 있다.
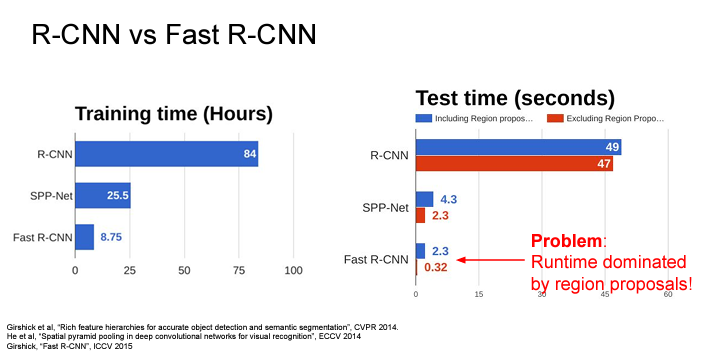
그래서 나온 Faster R-CNN
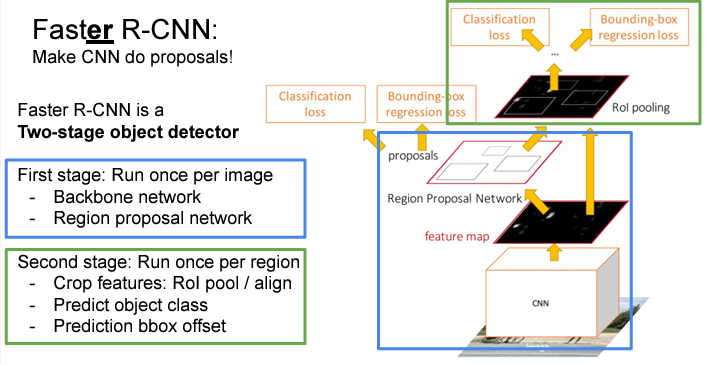
[ Faster R-CNN ]
Faster R-CNN 는 기존의 네트워크에서 병목현상이었던 region proposal 단계의 문제를 해결하기 위해서 네트워크 자체가 스스로 region proposal을 예측할 수 있도록 한다.
input 이미지에 대하여 CNN으로 feature map을 추출한 다음, Region Proposal Network (RPN)을 거치게 하여 네트워크가 feature로부터 직접 proposals를 예측할 수 있도록 한다. (위의 R-CNN과 다르게 이제 region proposal도 학습되는 것!)
나머지 부분들은 Fast R-CNN과 동일하게 각 proposal에 대하여 feature를 crop하고 어떤 물체인가에 대한 classification + bounding box 위치에 대한 regression을 수행하게 된다.

아까 위에서 언급했다 싶이 'Faster R-CNN'은 2-stage object detector이고 해당 2-stage를 도식으로 표현하면 아래와 같게 된다.
그렇다면, inference 속도가 더 빠르다고 한, 1-stage detector의 구조는 어떻게 되어 있는걸까?
[ Single-Stage Object Detectors ]

해당 방식의 모델들에 대한 논문들은 아래 링크에서 확인 가능.
https://paperswithcode.com/methods/category/one-stage-object-detection-models
Papers with Code - An Overview of One-Stage Object Detection Models
One-Stage Object Detection Models refer to a class of object detection models which are one-stage, i.e. models which skip the region proposal stage of two-stage models and run detection directly over a dense sampling of locations. These types of model usua
paperswithcode.com
이 방법은 object detection을 한 번에 하나의 regression problem으로 다룬다.
최종적으로 'Object Detection' task를 수행하기 위해서는,
CNN Backbone Network로 무엇을 이용할 것인가? Meta Architecture로 어떤 방법을 이용할 것인가? 이미지 사이즈는? Region Proposal의 갯수는? 등 다양한 것을 고려하여 조합해볼 수 있다.
아래 장표에서 이 방법들을 조합하여 실험해본 결과에 대한 논문도 소개해주고 있다.

3. Instance Segmentation
마지막, Instance Segmentation 태스크는 semantic segmentation과 object detection의 하이브리드(?) 같은 태스크이다.
Instance Segmentation is a computer vision task that involves identifying and separating individual objects within an image,
including detecting the boundaries of each object and assigning a unique label to each object.
The goal of instance segmentation is to produce a pixel-wise segmentation map of the image, where each pixel is assigned to a specific object instance.
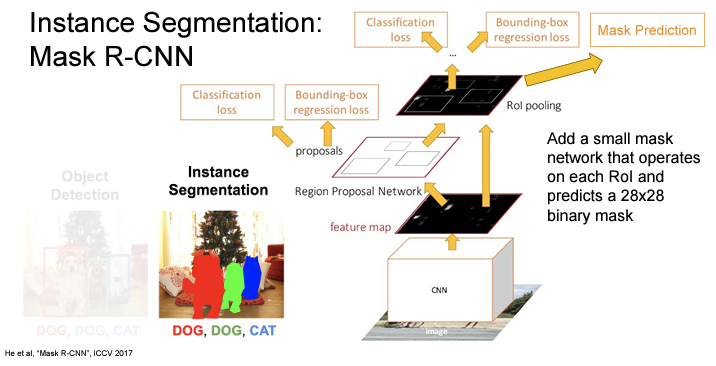
Mask R-CNN은 Faster R-CNN에서 각 region proposal에서 semantic segmentation을 한다고 생각해 볼 수 있다.

RoI Align 이후 위로 가는 과정 (classification scores / box coordinates)는 앞의 object detection에서 봤던 것과 동일.
더 나아가서 joint coordinates까지 훈련시킨다면 단순히 box coordinates를 넘어서 joint까지 detection이 가능해진다.

https://github.com/facebookresearch/detectron2
4. Beyond 2D Object Detection
- Object Detection + Captioning --> Dense Captioning
- Dense Video Captioning
- Objects + Relationships --> Scene Graphs
- Scene Graph Prediction
- 3D Object Detection (난이도 상)
- 3D Shape Prediction
결론 : task야 정말 끝도 없이 생성되는군..
'Study > 비전' 카테고리의 다른 글
| [OCR] 광학 문자 인식 기술 (2) (2) | 2024.07.12 |
|---|---|
| [OCR] 광학 문자 인식 기술 (1) (4) | 2024.07.07 |
| [Object Detection] R-CNN (0) | 2024.03.26 |