
가지치기에는 크게 2 종류가 있다.
가지치기는 과적합을 막아 새로운 데이터 (test data set)에 대한 실제 예측 정확성을 높임을 목표로 한다.
1. 사전 가지치기 (Pre-Pruning)
- 결정 트리가 다 자라기 전에 알고리즘을 멈추는 방법
- 나무의 최대 깊이 (max_depth), 잎의 최대 개수 (max_leaf_nodes), 노드가 분할하기 위한 데이터의 최소 개수 (min_samples_split) 등을 제어한다.
2. 사후 가지치기 (Post-Pruning)
- 결정 트리를 끝까지 그린 후 밑에서부터 가지를 쳐내는 방법
- 리프 노드의 불순도가 0인 상태의 트리를 생성한 후, 적절한 수준에서 리프노드를 결합한다.
여기서 내가 궁금했던 점
Q. 사후 가지치기에서 유의미하지 않은 노드를 정리하는데, 이를 결정하는 기준이 무엇인가?
Reduced-Error Pruning (REP), Rule Post Pruning, Cost Complexity Pruning 등 여러 형태의 가지치기가 존재하는데,
(1) Scikit-learn은 DecisionTreeClassifier( ) 클래스를 구현할 때 cost complexity parameter로 ccp_alpha를 제공함.
파라미터 값을 alpha 로 정했을 때 주어진 트리 T에 대하여 비용-복잡도의 지표를 아래식에서 R_alpha(T)라고 한다.
알파는 나무의 복잡도의 비중을 나타내는 하이퍼 파라미터이고, 값이 커질수록 모델은 간결해진다.
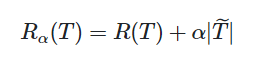
여기서 |T|는 terminal node의 개수를 말한다.
R(T)는 최종 terminal node에 대하여 오분류율을 나타낸다.
위 함숫값 (지표)가 최소화되는 방향으로 가지를 치는 알고리즘이 바로 Cost-Complexity Pruning인 것이다. (비용-복잡도 가지치기 방법)
(2) REP는
검증 데이터에 대해 오분류가 증가하는 시점에서 가지치기를 수행하는 알고리즘이다.
오류가 더 이상 줄어들지 않을 때까지 반복하면 되는 단순하고 직관적인 방법이지만 검증 데이터의 수가 적으면 필요 이상으로 가지치기 될 수 있다는 단점이 있다.
(3) Rule Post Pruning은
트리구조에서 맨 처음 루트노드에서부터 맨 끝 리프노드까지를 경로의 형태로 전환한다.
그 다음, 정확도가 낮은 순서대로 하나씩 제거해나가는 알고리즘이다.
참고자료
https://scikit-learn.org/stable/modules/tree.html#minimal-cost-complexity-pruning
https://scikit-learn.org/stable/auto_examples/tree/plot_cost_complexity_pruning.html
'Study > 머신러닝' 카테고리의 다른 글
| 차원 축소 (0) | 2023.10.29 |
|---|---|
| 앙상블 학습 - Bagging (0) | 2023.09.25 |
| Decision Tree : scikit learn의 feature_importances_는 어떻게 계산된 것일까? + Permutation Importance (1) | 2023.09.08 |
| Decision Tree : 데이터 분할에서 '균일도'(impurity)에 대하여 (1) | 2023.09.07 |
| PR Graph 성능 평가 (2) | 2023.09.07 |