
Human Language and Word Meaning
■ How do we represent the meaning of a word?
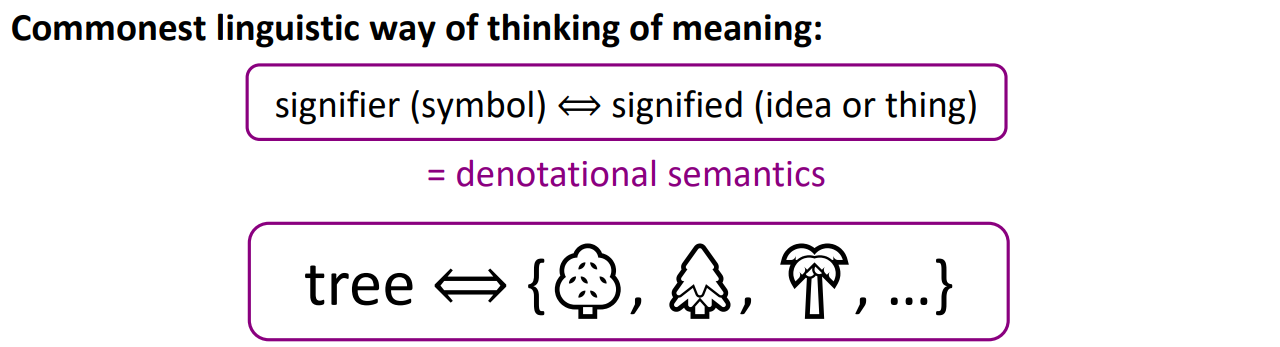
■ How do we have usable meaning in a computer? : WordNet
그런데, 어떻게 컴퓨터에 'tree'를 'tree가 나타내는 것들'을 연결해서 입력시켜주지?
전통적 NLP Solution : Use Wordnet, a thesaurus containing list of synonym sets and hypernyms (relationship)

WordNet의 한계 : 뉘앙스를 놓치는 경우, 새로운 단어, 의미 (신조어) 등록 x, 주관적, 정확한 단어 유사도 측정이 불가능
■ Representing words as discrete symbols : One-Hot vectors
전통적인 방식 : 1 단어 1 표현, 국소 표현 (localist representation) :
해당 단어 자체만 보고 특정 값을 매핑하여 단어 표현
차원이 vocabulary size인 원-핫 벡터로 각 단어들을 표현함 (희소벡터 ; sparse vector)
→ 문제 :
(1) Curse of Dimensionality : 단어 종류가 얼마나 많은데.. 차원이 너무 커짐,
(2) Orthogonality : 관계 / 유사도 표현에 한계 (예를 들어 유사어인 'motel'과 'hotel'인데도 원핫벡터로는 직교하게 됨, 유사도가 0?)
→ 해결 : learn to encode similarity in the vector themselves
■ Representing words by their context : Word Embeddings
분산표현 (Distributional representation) : 주변에 자주 등장하는 단어들에 의해 뜻이 정해짐

1단어 1 벡터 : 밀집벡터(;dense vector) : 유사 문맥에 함께 등장하는 단어들과 그 유사도(내적값)가 높도록 벡터가 정해짐

Word2vec
■ Word2vec
단어의 '의미'를 다차원 공간에 벡터화하는 표현 방법인 '분산표현방법'(distributional hypothesis)을 차용
비슷한 위치에 등장하는 단어들은 비슷한 의미를 가지도록 학습시키는 방법이 'Word2vec'
(중심단어가 주어졌을 때 문맥단어가 등장할 확률을 최대화하도록 word vector 조정)

참고 : https://wikidocs.net/22660
[ 학습시키는 방법 기술은 아래 구분선 안에, 목적함수를 최소화하는 연산 과정은 생략 - 강의 참고 ]

윈도우 사이즈=m일때 중심단어의 위치를 옮겨가면서 해당 중심단어 주변에 문맥단어가 올 확률을 최대화하도록 Likelihood L를 잡고, - log를 취한 Objective function J를 잡는다. J가 최소가 될 때 예측 정확도가 최대가 됨.
저 확률 P(w_t+j | w_t)을 계산하기 위해서
어떤 단어 w가 '중심단어'로 사용될 때 중심단어와 hidden layer간의 가중치는 v_w로,
'문맥단어'로 사용될 때는 문맥단어와 hidden layer간의 가중치는 u_w로 표기한다.

P(o|c) = 중심단어로 'c'가 나올때 문맥단어로 'o'가 나올 확률
단어사전의 모든 단어가 중심단어 'c'의 문맥단어로 나올 경우 대비 (분모)
'o'가 중심단어 'c'의 문맥단어로 등장할 경우를 (분자)
softmax 함수로 확률로 만들어줌
는 (내적값) 중심 벡터와 맥락 벡터간 코사인 유사도를 의미

2dV개의 파라미터가 학습되고 각 단어 별로 d차원의 두 개의 벡터가 훈련결과로 나올 것이다.
( 1. 문맥단어로서의 word vector , 2. 중심단어으로서의 word vector)
여기서 두 개의 word vector를 하나의 word vector로 만드는 방법은 여러 가지가 있지만,
강의에서는 평균으로 구할 수 있다고 소개하고 있다.
※ 강의
https://www.youtube.com/watch?v=rmVRLeJRkl4&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=1
※ 강의자료
https://web.stanford.edu/class/cs224n/index.html#schedule
※ 참고자료
https://wikidocs.net/22885
'Study > 자연어처리' 카테고리의 다른 글
| [cs224n] Lecture3 - Backprop and Neural Networks (0) | 2024.01.21 |
|---|---|
| [cs224n] Lecture2 - Word Vectors and Language Models (1) | 2024.01.14 |
| ChatGPT Prompt Engineering for Developers : Chatbot (0) | 2023.12.15 |
| ChatGPT Prompt Engineering for Developers : Usage (2) (0) | 2023.12.14 |
| ChatGPT Prompt Engineering for Developers : Usage (1) (1) | 2023.12.14 |