
본격적으로 Neural Network에 대한 이야기를 하기 전에 neural network가 사용되는 nlp task를 보면서 넘어가자고 한다.
Named Entity Recognition
오 일하면서 지겹도록 듣는 ner이다.
NER task는 텍스트에서 인명, 지명과 같은 고유명사를 찾아, 분류하는 태스크이다. 예를 들어, 다음과 같은 두 문장이 있다고 하자.
① Last night, Paris (PER) Hilton (PER) wowed in a sequin gown.
② Samuel (PER) Quinn (PER) was arrested in the Hilton (LOC) Hotel (LOC) in Paris (LOC) in April (DATE) 1989 (DATE).
→ 여기서 두 문장은 전혀 다른 corpus에서 가져온 문장들이라, dictionary를 기반으로 ner 태스크가 진행된 것이 아닌, 문맥으로 ner 태스크가 진행되었다. 그래서 보면 같은 단어 'Paris'인데 1번 문장에서는 'Person'이라는 엔티티로, 2번 문장에서는 'Location'이라는 엔티티로 인식된 것이다.
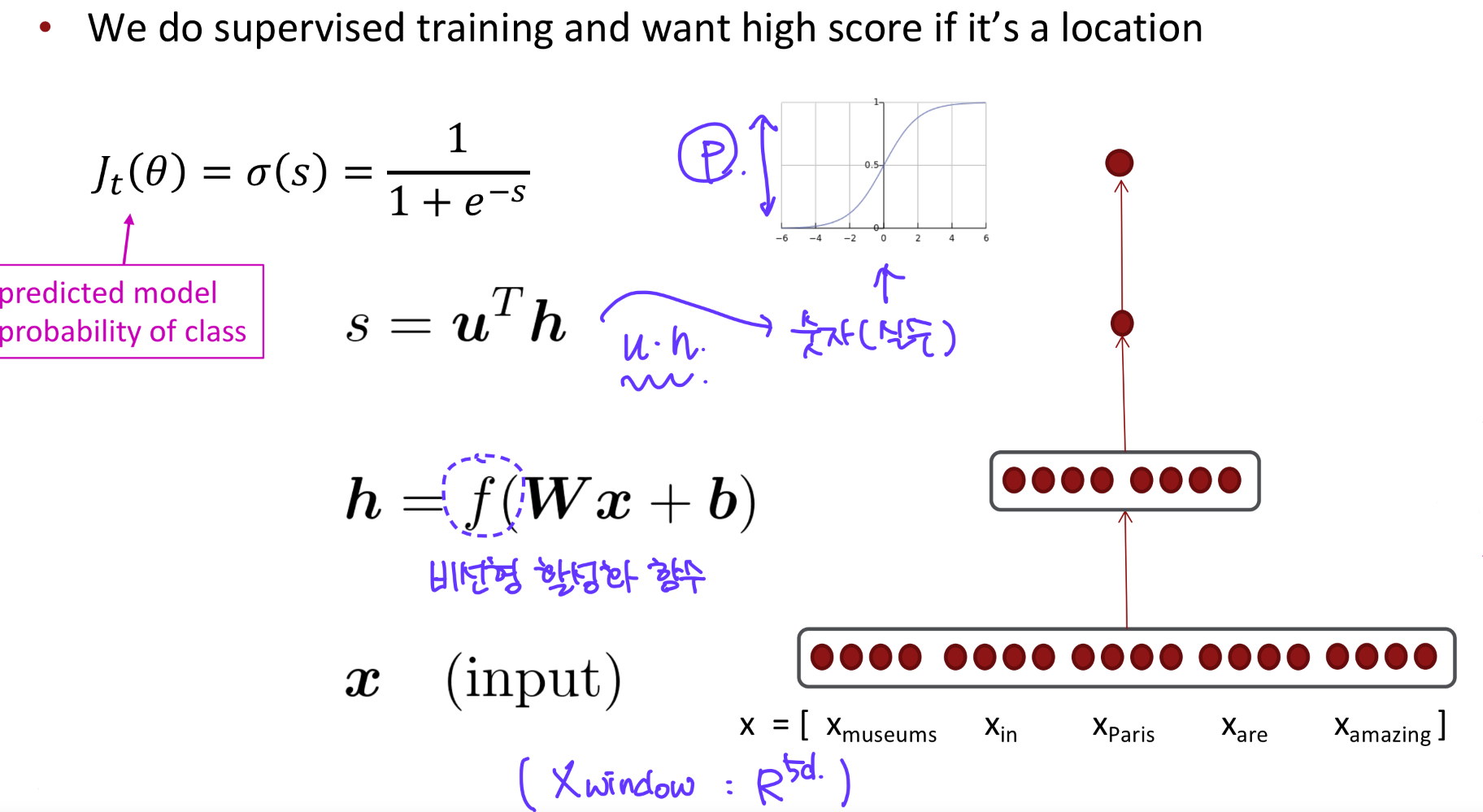
간단한 NER : 윈도우 기반 분류 (binary logistic classification)
→ Idea : 이웃하는 단어들, 문맥 윈도우를 이용하여 각 단어들을 특정 카테고리로 분류하는 것
→ Method : 로지스틱 분류기를 hand-labeled data를 기반으로 훈련시켜서 특정 class에 속하는지 or 속하지 않는지 분류함, 이때 사용되는 word vector는 중심단어 + 문맥단어 (윈도우크기가 n일때 2n개)
(물론 여러가지 class로 분류하도록 훈련시키려면 multi-class softmax 이용)

Gradients, Chain Rule and Jacobian
강의에서는 gradient를 직접 손으로 계산해보는 과정도 소개해준다. 간단하게 요약해서 정리하면 아래와 같다.


In Nerual Net
원래는 손실함수 J의 gradient를 계산하여 파라미터를 업데이트 해야 함이 맞지만,
계산의 간소화를 위해 score의 b(bias)에 대한 gradient를 계산해 보겠다고 한다.


score의 b(bias)에 대한 gradient를 계산했으니까
이제 score의 W (weight)에 대한 gradient를 계산해볼 차례이다.

출처 :
https://www.youtube.com/watch?v=X0Jw4kgaFlg&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=3
https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1234/
'Study > 자연어처리' 카테고리의 다른 글
| [cs224n] Lecture 15 - Code Generation (1) | 2024.03.24 |
|---|---|
| Gemma (1) | 2024.03.09 |
| [cs224n] Lecture2 - Word Vectors and Language Models (1) | 2024.01.14 |
| [cs224n] Lecture1 - Word Vectors (2) | 2024.01.07 |
| ChatGPT Prompt Engineering for Developers : Chatbot (0) | 2023.12.15 |