
출처 : stanford cs224n 강의를 듣고 작성한 페이지입니다.
https://www.youtube.com/watch?v=JlK46EzImM8&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=16
1. Background : Program Synthesis
- 프로그램을 짜는 프로그램
- program synthesizer : program that takes a specification and outputs a program that satisfies it
- 어떤 specification ??
- a logical formula / 같은 algorithm을 더 빠르게 / 정해진 input, output에 맞는 식 / Natural language descriptidon
- ex. 정말 간단하게 엑셀 프로그램에서 'FlashFill'기능에서 "Jan", "Feb"을 "January", "February"로 바꿔주는 것도 하나의 예시
2. Program Synthesis as Pragmatic Communication
Ambiguity in natural language
- 대화 속에서 자연어를 이해하는데 큰 문제가 생기진 않지만, 이를 컴퓨터가 이해하게 하는 것은 어려울 수 있다.
- 예를 들어, Winograd Schema Challenge 문제에서
"The city councilmen refused the demonstrators a permit because they feared violence" 와
"The city councilmen refused the demonstrators a permit because they advocated violence" 두 문장에 대해서
인간은 쉽게 'the city councilmen'이랑 'the demonstrators'의 역할이 구분이 되기 때문에 'feared' / 'advocated' 동사에 따른 they가 지칭하는 바의 구분이 가능하지만 실상 매우 모호한 문제이다.
Pragmatic Reasoning
- 주어진 단어, 문장의 의도된 뜻을 추론할 수 있는 것
- 인간이 의사소통할 때 소통하는 상대방이 정보를 더 많이 주는 방향으로 말을 할 것이라는 전제가 깔려있음
- Rational Speech Act (RSA) : views communication as recursive reasoning between a speaker and a listener
간략하게 예를 들어 설명해보자.
세 개의 물체 (blue square, blue circle, green square) 중 하나를 indicate하기 위한 space of utterances으로 {"blue", "green", "circle", "square"}이 있다고 하자. 이때 utterance가 "blue"이었다면 pragmatic speaker & listener은 세 개의 물체 중 어떤 것으로 특정지을 수 있을까?라는 문제에 대해서 ::
Literal listener은 blue square, blue circle의 확률이 50:50이라고 생각하는 반면에
Pragmatic listener은 blue square을 언급하고 있을 확률을 더 높게 계산하여 blue square을 가리키는 것이라고 판단할 것이다. 왜? listener의 머릿속에는 동시에 < speaker가 "circle"이라고 말하면 literal listener도 바로 blue square가 아닌, blue circle로 특정지을 수 있을 것이라고 생각하고 말한다 > 고 이해하기 때문이다. 즉, blue circle을 가리키고 싶었다면 그냥 circle이라고 말하지, blue라고 말하지 않았을 것.
통계적으로 RSA 계산방법을 적용하면 그 확률이 60:40으로 계산된다고 한다. (생략)
Program Synthesis as Pragmatic Communication
- program synthesis에서는 utterance가 specification으로 입력되는 것이다.

- 그리고 자연어에서의 ambiguity를 프로그램이 다룰 수 있는 방법은 RSA-style reasoning인 것이다.
- 만약에 pragmatic synthesizer를 이용한다면 더 적은 example로도 원하는 output을 낼 수 있는 program을 만들 수 있는 것이다.
3. Program Synthesis with Language Models
LLM이 확률 기반으로 텍스트 generation을 하는 것과 같은 원리이다.
GPT-3도 code generating task를 위해 훈련시키지 않았지만 간단한 파이썬 함수들을 잘 생성해냄.
그래서 오픈AI에서 개발한 OpenAI Codex 모델은 자연어 input을 분석하여 code를 생성하는 모델로, 방대한 오픈소스 코드 데이터를 학습시킨 결과이다. (copilot 백엔드 모델이라고 한다.)
--------------------
[ Benchmark for Code Generation ]
그렇다면 그 language model은 어떻게 평가하는 것일까?
Codex 논문에서는 'HumanEval' 이라고 164개의 파이썬 문제 : (자연어) -> (코드) 의 benchmark를 만들었다.
이 문제를 얼마나 잘 푸는지에 대한 성능 지표는 Pass@k로, 생성된 top-k개의 code샘플들에 대해서 적어도 하나는 맞을 확률을 의미한다.

해당 벤치마크로 GPT3, Codex, 파인튜닝된 Codex(Codex-S)를 실험해 보았을 때, (당연하게도) GPT3 < Codex < Codex-S 순으로 좋은 성능을 내고 있음을 확인할 수 있다.
------------------------
[ Sampling vs Temperature ]
pass@k로 모델을 평가할 때, k값에 따라서 최적의 temperature를 고르는 것이 중요하다.

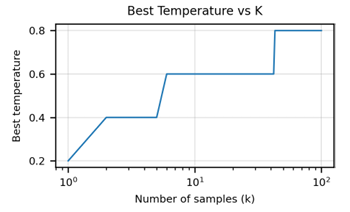
위 그래프에 따르면 k가 클 때는 temperature가 높은 것이 더 최적이다.
왜냐하면 temperature가 높을수록 생성물(generated code)의 다양성이 더 커지기 때문이다.
------------------------
[ Ranking ]
그런데 당연히, 사용자에게는 막 100개의 생성된 코드를 보여주지는 않을 것이다. 그래서 이용하는 방법은,
(1) 애초에 k값을 작게 : 더 적은 수의 프로그램을 샘플링하는 것
(2) k값은 유지 : 그대로 많은 수의 프로그램을 샘플링하되, 순위를 다시 매기고 그 중에서 다시 top k를 보여주는 것 (여기서 k는 더 작은 k)

Codex 논문에서는 위에서처럼 docstring으로부터 code를 생성하는 것뿐만 아니라, code로부터 docstring을 만들어내는 것도 도전한다. 이 태스크는 기존의 code generating task보다 훨씬 성능이 떨어졌다. (fine-tuning을 해도 여전히 낮은 성능을 보임)
----------------
[ AlphaCode ]
2022년 DeepMind에서 AplhaCode를 출시했다.
Codex와 다르게 알파코드는 문제를 더 빠르게 인코딩하기 위해서 인코더-디코더 트랜스포머를 이용했고, multi-head attention 대신에는 multi-query attention을 이용했다.
훈련과정에 대한 파이프라인은 다음과 같다.
Pre-training 단계 : 깃헙 코드소스를 기반으로 cross-entropy loss training
Fine-tuning 단계 : 프로그래밍 문제들에 대한 human solutions를 기반으로 훈련 (문제는 주석처리)
- RL fine-tuning (GOLD 방법) : 일반 RLHF와는 조금 다르게 모든 generated solution이 맞도록 하는 방향이 아니라 하나라도 맞추게 학습
- Value-conditioning : 틀린 submissions를 이용해서 training data를 증강시킴 ( 틀린 solution에 대해서는 틀렸다는 주석 첨가 )
Sampling : 한 문제에 100k개 정도의 답변을 샘플링 (large scale)
Filtering : 문제에서 주어진 test case를 pass하는 샘플들만 필터링 (이 과정에서 거의 99%가 필터링됨)
Clustering : 기존에 pretrained model checkpoint로부터 test input을 생성해내는 모델을 따로 훈련시키고, 여기서 생성된 test input을 넣었을 때 비슷한/동일한 답을 생성하는 프로그램끼리 clustering

성능은 모델의 파라미터 수, 컴퓨팅 시간, 샘플(generation)의 수, 데이터셋에 비례했다. ( log-linearly) 단, submission 수를 10번으로 제한했던 성능지표 '10@k'에서는 샘플수에 비례하여 증가하는 추세가 살짝 꺾였다. 또한, fine-tuning 단계에서 이용한 방법들 및 filtering, clustering을 단계적으로 적용했을 때 적용함에 따라 점차 성능이 증가함도 확인되었다.
4. Programs as Tools For Language Models
사람이야 문제를 해결하기 위해서 다양한 툴을 이용하지만 language model은 그렇지 못한다는 한계가 있다.
한 번 훈련시키면 정해진 그 체크포인트로 문제를 해결해야하기 때문이다.
Minerva (llm trained on mostly math) 는 여전히 수학 문제 해결에서 종종 연산 오류를 범하고 있다.
따라서 연산을 할 때, decoding 과정에서 특정한 special token이 input으로 들어오면 확률론적으로 다음 output을 예측하는 것이 아니라, 실제로 calculator를 이용하여 연산 실수에 대한 정확도를 높이는 방법이 있었다.
또, 'Toolformer'의 경우에는 필요한 경우에 API를 이용해 외부 툴 (계산기, 검색엔진) 등을 활용할 수 있도록 하였다.
5. Limitations and Discussion
- 훈련시키는 코드 자체에 에러가 있을 수 있기 때문에,
- 현재 오픈 소스 코드가 새로운 라이브러러, 언어 등을 모두 담을 수 없기 때문에,
- 생성된 코드는 버그가 있을 수 밖에 없다.
'Study > 자연어처리' 카테고리의 다른 글
| Text generation & Machine Reading Comprehension (0) | 2024.04.09 |
|---|---|
| Text Classification (+Benchmark & Evaluation) (1) | 2024.03.24 |
| Gemma (1) | 2024.03.09 |
| [cs224n] Lecture3 - Backprop and Neural Networks (0) | 2024.01.21 |
| [cs224n] Lecture2 - Word Vectors and Language Models (1) | 2024.01.14 |