
★ 아래의 글은 이전에 포스팅했던 Attention&Transformer 글을 (1)/(2)로 나누고 재정리한 글입니다.
출처
- https://youtu.be/AA621UofTUA?si=1wD9tdEATVo0Tkt7
- 학교 자연어처리 수업
- https://web.stanford.edu/class/cs224n/slides/cs224n-2024-lecture08-transformers.pdf
목차
◈ Attention & Transformer (1)
1. Seq2Seq의 구조
2. 기존 Seq2Seq 모델의 한계
3. Seq2Seq에 Attention을 추가
- Attention Mechanism
- Seq2Seq with Attention
- 다양한 종류의 Attention
◈ Attention & Transformer (2)
4. Transformer
2024.04.10 - [Study/자연어처리] - Attention & Transformer (2)
1. Seq2Seq의 구조

- 입력 sequence, 'I am a student' 의 각 단어를 embedding vector로 변환 후 순차적으로 입력한다.
- 인코더의 마지막 셀 (RNN이든, LSTM이든)에서 Input Sequence의 정보를 모두 담은 벡터를 출력한다. = CONTEXT Vector
- context vector는 decoder의 입력 값으로 사용된다.
- 디코더로부터 출력 sequence, 'je suis etudiant' 가 출력된다.
즉, 입력 시퀀스를 처리하는 부분을 인코더(encoder) / 출력 시퀀스를 생성하는 부분을 디코더(decoder)라고 한다.
2. 기존 Seq2Seq 모델의 한계
- 고정된 크기의 context vector v에 input sequence 전체의 정보를 압축한다.
- 이때, 병목(bottleneck)이 발생하여 성능 하락의 원인이 된다.

- Decoder가 context vector를 매번 참고할 수 있도록 하여 (긴 문장에 대해서) 성능을 개선(정보 손실을 줄일 수 있음)할 수도 있음
- 그러나 여전히 (긴) input sequence를 하나의 벡터에 압축해야 하기 때문에 병목현상 발생

[ 문제상황 ]
- 하나의 context vector가 input sequence의 모든 정보를 가지고 있어야 하므로 성능이 저하됨
[ 해결방안 ]
- 매번 input sequence에서의 출력 전부를 입력으로 받을 수 있는 다른 방법?
3. [해결방안] : Seq2Seq 에 Attention을 추가
3-1 Attention Mechanism
예측할 단어와 가장 의미가 유사한 입력 단어를 더 참고할 수 있도록 가중치를 구하여 값에 곱한 정보를 압축한 Attention Value 출력
Attention (Q,K,V) = Attention Value
- Query : 예측하고자 하는 단어 벡터
- Key : 모든 입력 단어들의 벡터
- Value : Key의 의미를 나타내는 벡터

[ Attention Weight layer ]
Query와 Key의 연관성을 구함
- Query와 Key 벡터 간의 거리를 구하기 위해 내적 연산 수행
- Attention Score에 Softmax 함수를 적용하여 Query와 Key의 연관도 값을 확률로 나타냄
[ Weighted Sum layer ]
확률값 (attention score)과 Value를 가중합하여 문장의 정보를 압축한
Attention Value로 출력
3-2 Seq2Seq with Attention
https://arxiv.org/abs/1409.0473
긴 문장의 정보를 모두 context vector에 넣고 이를 decoder의 입력으로 사용하는 것과 다르게,
긴 문장의 정보 손실을 방지하고자 Decoder의 각 시점마다
Encoder의 모든 hidden state vector와 내적하여 weighted-sum vector를 활용하여 output을 출력한다.
디코더에서 현재 t 시점의 hidden state 을 s_t 라고 하자 [QUERY]
그리고 인코더에서 각 시점마다 만들어진 hidden state 는 h_t 라고 하자 [KEY]
(여기서 두 벡터의 임베딩차원은 동일!)
인코더의 모든 출력을 참고하기 위해서 모든 시점의 h_t 와 내적(dot product)을 수행한다. (유사도 계산)
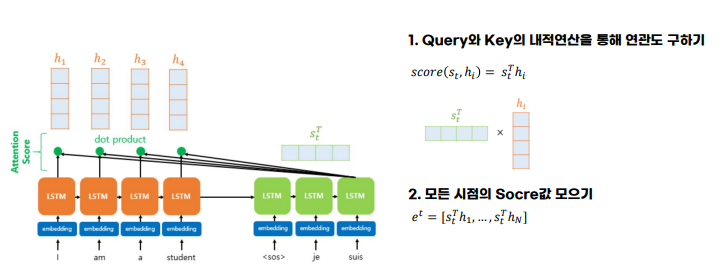
- 각 내적값(attention 연산을 취한 값) = Attention Score에 softmax를 취하면 각각의 값은 총합이 1인 확률분포로 나타내어짐
- 이를 Value와 가중합하면 최종으로 Attention Value : a_t 가 출력된다.
즉, 한 단어를 decoder에서 출력할 때마다 input의 어떤 단어에 더 attention 할지 보는 것이다.

이러한 어텐션 값 a_t은 종종 인코더의 문맥을 포함하고 있다고하여, 컨텍스트 벡터(context vector)라고도 불린다.
이는 seq2seq에서는 인코더의 마지막 은닉 상태를 컨텍스트 벡터라고 부르는 것 과는 다르다 !!!
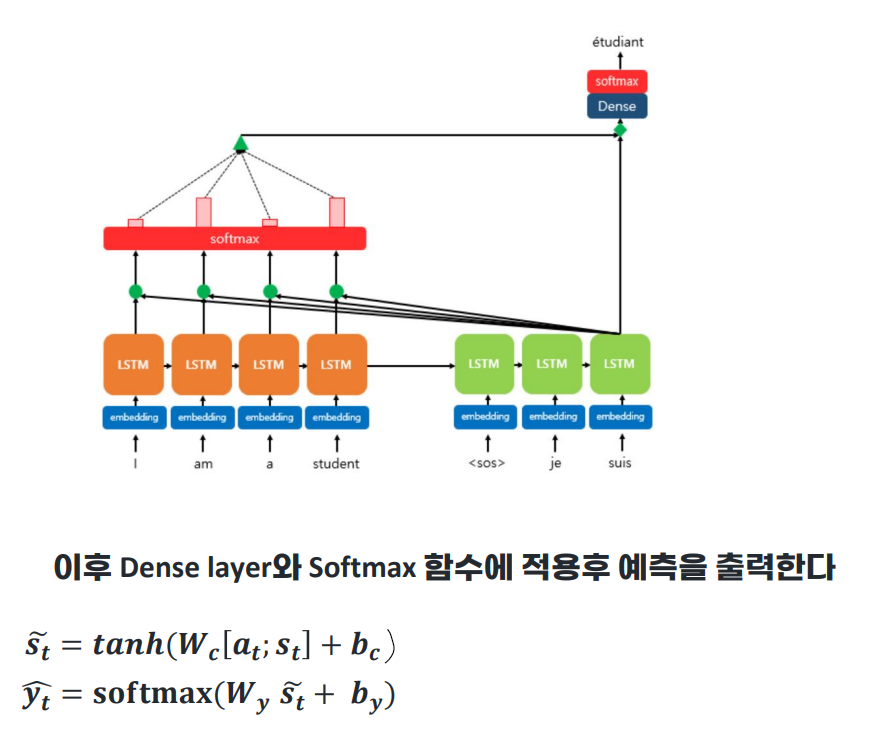
이제 어텐션 함수의 최종값인 Attention Value : a_t를 구했으니까, 디코더에 반영할 차례이다.
a_t와 s_t를 concatenate하여 하나의 벡터로 만들어준다. 이를 v_t라고 정의하자.
이 v_t를 디코더의 다음 토큰(y hat)을 예측하는 연산으로 입력하여 인코더의 정보를 활용하여 y hat 을 조금 더 잘 예측할 수 있게 된다.

트랜스포머 논문에서는 위의 v_t를 바로 출력층으로 보내기 전에 신경망 연산을 한 번 더 수행한다.
학습이 가능한 가중치 행렬 W_c 와 곱해준 후, 하이퍼볼릭탄젠트 함수를 지나도록 하여 출력층 연산을 위한 새로운 벡터 s_t를 얻고,
이를 출력층의 입력으로 사용한다.
기존 seq2seq에서 입력 : context vector와 전 시점의 출력 s_(t-1)
with attention에서 입력 : attention value (a_t)로부터 얻은 새로운 벡터 s_t (아래 그림에서는 s_t hat)와 전 시점의 출력 s_t-1
Attention 가중치가 더 높을수록, 각 출력이 해당 입력을 더 참고했다 (attention 했다)고 할 수 있으므로
아래 표에서 색이 더 밝게 보이게 된다.

3-3 다양한 종류의 Attention
뉴럴넷에 사용할 수 있는 어텐션에는 다양한 종류가 있다.
위에 설명한 어텐션은 "dot-product attention"이다. 이 외의 어텐션들과 이 어텐션의 차이점은 s_t와 h_t를 어떻게 연산하느냐의 차이이다.
(= attention score 함수)

'Study > 자연어처리' 카테고리의 다른 글
| [cs224n] Lecture 9 - Pretraining (1) (0) | 2024.04.22 |
|---|---|
| Attention & Transformer (2) (1) | 2024.04.10 |
| Text generation & Machine Reading Comprehension (0) | 2024.04.09 |
| Text Classification (+Benchmark & Evaluation) (1) | 2024.03.24 |
| [cs224n] Lecture 15 - Code Generation (1) | 2024.03.24 |