
★ 아래의 글은 이전에 포스팅했던 Attention&Transformer 글을 (1)/(2)로 나누고 재정리한 글입니다.
출처
- https://youtu.be/AA621UofTUA?si=1wD9tdEATVo0Tkt7
- 학교 자연어처리 수업
- https://web.stanford.edu/class/cs224n/slides/cs224n-2024-lecture08-transformers.pdf
목차
◈ Attention & Transformer (1)
1. Seq2Seq의 구조
2. 기존 Seq2Seq 모델의 한계
3. Seq2Seq에 Attention을 추가
- Attention Mechanism
- Seq2Seq with Attention
- 다양한 종류의 Attention
2024.01.30 - [Study/자연어처리] - Attention & Transformer (1)
◈ Attention & Transformer (2)
4. Transformer
5. Input 임베딩 + Positional Encoding
6. Attention
- Multi-Head Attention
- Encoder Self Attention
- Masked Decoder Self Attention
- Encoder-Decoder Self Attention
7. Final Layer
8. 논문 결과물
RNN에서 back propagation의 기울기 소멸 문제로 인한 긴 seq에 대한 한계를 극복하기 위해 LSTM,
여전히 긴 seq에서 중요한 정보를 모두 담을 수 없고 마지막 context vector에 인코딩된 모든 정보가 담김으로써 병목이 발생한 문제를 해결하기 위해 LSTM+attention(seq2seq w/t attention)으로 발전했었다.
4. Transformer
논문 : Attention is All You Need(2016)
sequential modeling (rnn, lstm)을 전혀 사용하지 않고 오로지 attention만을 이용하여 만든 구조
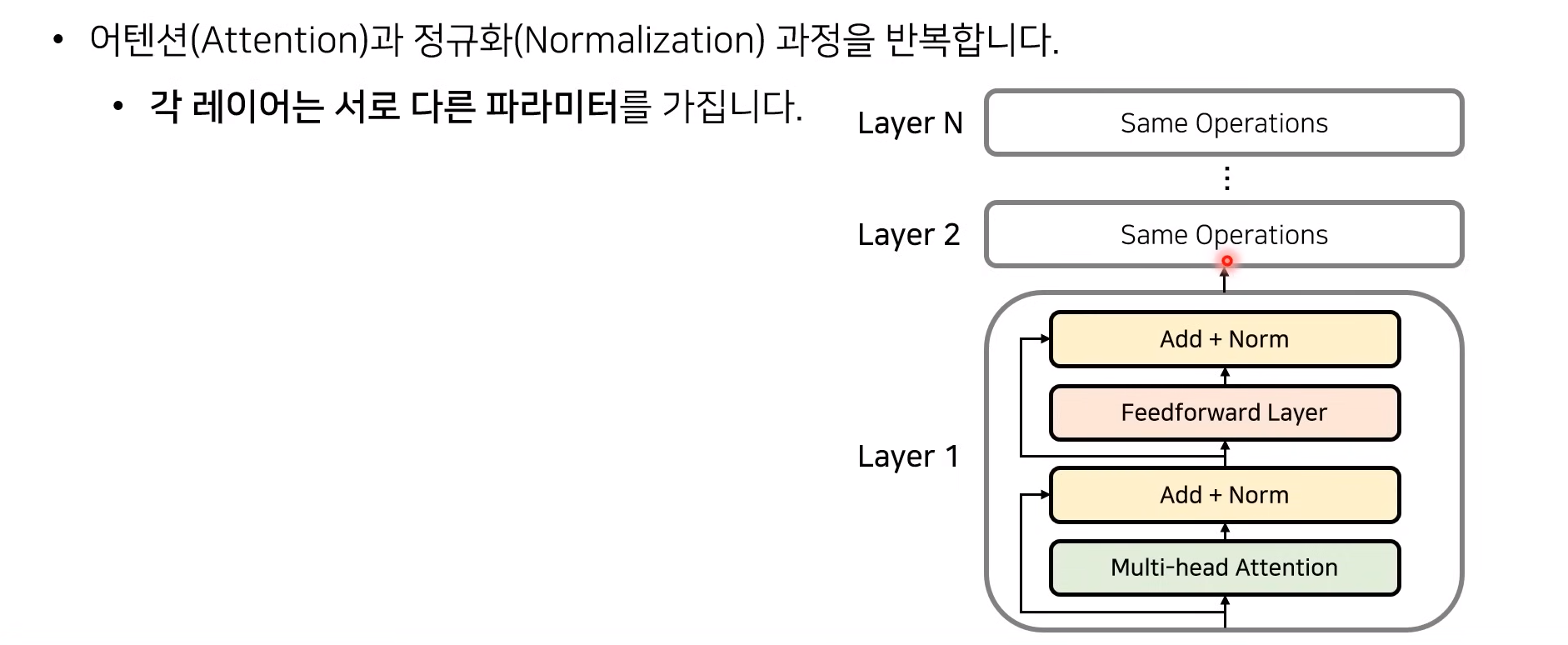
- 어텐션 (multi-head attention) 의 병렬적 사용을 통해 효율적 학습이 가능한 구조의 모델
- Encoder & Decoder 아키텍쳐 (초기 버전은 6개 인코더 + 6개 디코더, 각 레이어는 서로 다른 파라미터를 이용함 - 이 말은 레이터 갯수를 늘리면 파라미터 수가 무한정 많아진다는 것, 하지만 같은 구조를 공유하기 때문에 확장성이 좋음)

▶ Encoder ⊃ 2개의 하위 레이어

(1) Self-Attention
input sequence의 각 단어들에 대해 어텐션을 수행 (정보를 찾고자 하는 대상과, 제공하는 대상이 같기 때문에 self-attention)
(2) Feed Forward Neural Network
(셀프 어텐션을 거친) 모든 위치의 단어들에 대하여 동일한 구조(파라미터)의 FFNN이 독립적으로 적용
▶ Decoder ⊃ 3개의 하위 레이어

(1) Self-Attention
마스킹이 적용된 self attention
(2) Encoder-Decoder Attention
인코더와 디코더 간의 어텐션 (디코더의 특정 토큰이 input의 어떤 토큰과 관련이 있는지 파악을 위함)
Masking을 하는 이유는 디코더가 현재 시점 보고 있는 토큰 이후 시점의 토큰들의 정보를 사용하지 않기 때문이다.
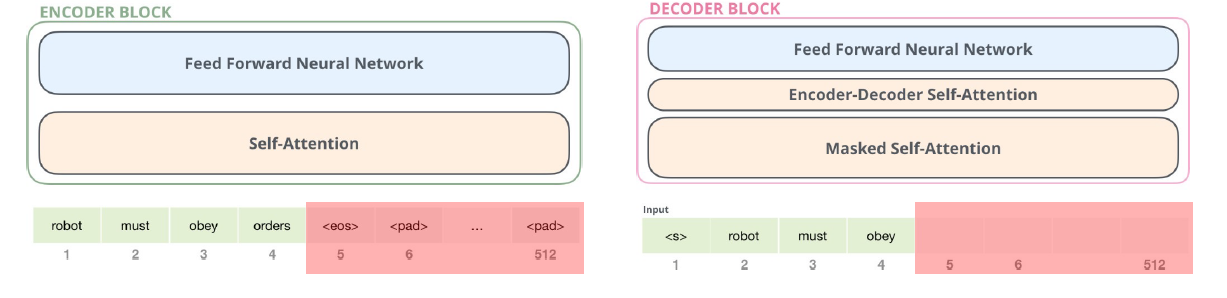
(3) Feed Forward Neural Network
인코더와 동일한 방식의 FFNN
[ Position-wise Feed-Forward Networks ]

self attention의 결과물은 FFNN을 위치에 따라 독립적으로 거친다.
왜냐하면 self attention 연산은 그래봤자 weighted sum : 선형 결합이기 때문이다.
따라서 FFNN으로 Non-Linearity를 추가해준다.
FFN(x) 함수를 보면 Linear layer (xW1+b1) 통과 - ReLU 함수 통과 - Linear layer (xW2+b2) 통과 순으로 구성됨.
- 같은 인코더 블록 안에서는 동일한 가중치를 사용하고,
- 다른 인코더 블록 간에는 다른 가중치를 학습한다. (6개)
- W1은 512 x 2048 의 행렬 / W2는 2048 x 512 의 행렬
트랜스포머 모델의 전반적인 구조와 특징에 대해 알아보았으니
아래에서는 개별적 역할 및 기능에 대해 자세히 알아보자.
5. Input 임베딩 + Positional Encoding
① input 임베딩
개별 단어에 대한 임베딩 벡터(512차원)를 최초 입력으로 사용한다. (이는 학습될 수도 있고, 사전 훈련된 임베딩을 적용할 수도 있음)
이 때, 단어 임베딩은 첫번째 레이어의 인코더에서만 입력으로 1회 사용되고, 나머지 레이어의 인코더 입력들로는 그 전 레이어의 인코더 출력물이 사용된다. 단, 여기서 512라는 값은 hyperparameter로, 컴퓨팅 자원에 따라 더 늘릴수도 줄일수도 있다.
② positional encoding
RNN을 사용하지 않는 Transformer는 단어를 순차적으로 입력받지 않고 한번에 받는 구조이다.
따라서 입력 sequence에서의 단어들 간의 위치 관계를 표현해줄 수 있는 방법이 필요하고, 이 방법이 Positional Encoding" (위치 인코딩)
input embedding 벡터와 같은 차원(512)의 positional encoding 벡터를 elementwise로 더해줌으로써 각각의 단어가 어떤 순서에 있는지에 대한 정보를 담게 해준다.
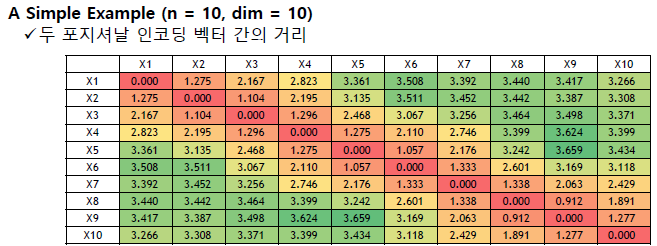
positional encoding의 함수는 아래 그림과 같은데, 이는 포지셔날 인코딩이 반영해야 하는 특성을 담은 함수로 설계된 것이다.
1. 각 단어의 위치에 대해서 인코딩 벡터는 서로 달라야 한다. (unique)
2. 모든 위치에서 인코딩 벡터의 크기가 512로 동일하다.
3. 두 단어 사이의 거리가 멀수록 인코딩 간 거리가 멀도록 설계되어야 한다. (아래 우측 그림 참고)

6. Attention
■ Multi-Head Attention
기본적으로 트랜스포머에서 사용되는 어텐션들은 모두 multi-head attention이다.
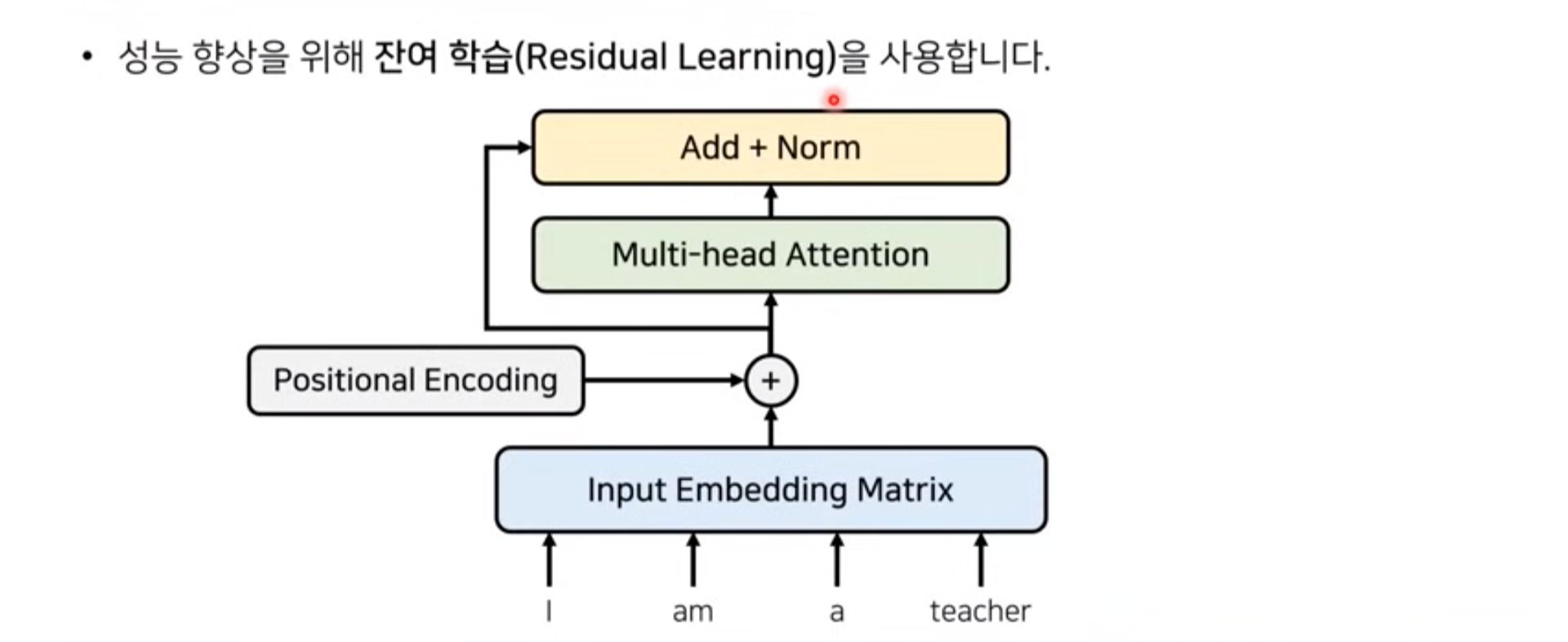
▶ Residuals / Normalization
위에서 인코딩된 결과물 (인코딩벡터)는 바로 multi-head attention을 수행하기 위해 입력되거나,
입력되지 않은 벡터는 (residuals) 위의 attention 수행 output과 더해진 후, 정규화 과정(Normalization)을 거친다.

Transformer의 encoder와 decoder에서 사용하는 ATTENTION은 여러 개의 head를 가지고 있는, 'Multi-Head Attention' 구조를 가짐


이해의 편의를 위하여 Self Attention 부터 설명하면서, 왜 이것이 'Multi-Head'의 구조인지 설명하겠다.
■ Encoder Self Attention
① 입력 벡터에 대해서 3가지 벡터 (q,k,v) 를 생성
- 쿼리(Q) : 인코딩을 수행하는 특정 단어가 시퀀스 내의 다른 단어와 어떠한 연관성을 갖고 있는지 묻는 주체
- 키(K) : Q의 물음을 받는 단어들 (객체)
- 값(V) : Attention Weight와 곱해지는, 가중합을 구하게 하는 키 단어들의 V 벡터

② Q와 K를 곱하여 Attention score(집중도)를 계산
- 하나의 토큰을 각각의 key 단어들과 곱해서 sequence length(아래 도식에서는 4)만큼의 attention score(스칼라값)을 구하고
- scaled-dot product 이기 때문에 scaling을 위하여 q/k/v 벡터 차원(64)의 루트 값 (8)으로 나눠준다.
- 이는 벡터 차원이 커질수록 Q*K^T 값이 커져서, softmax를 취했을 때 확률분포가 거의 uniform하게 나오기 때문이다. (이를 방지하기 위해 나눠준다는 뜻)
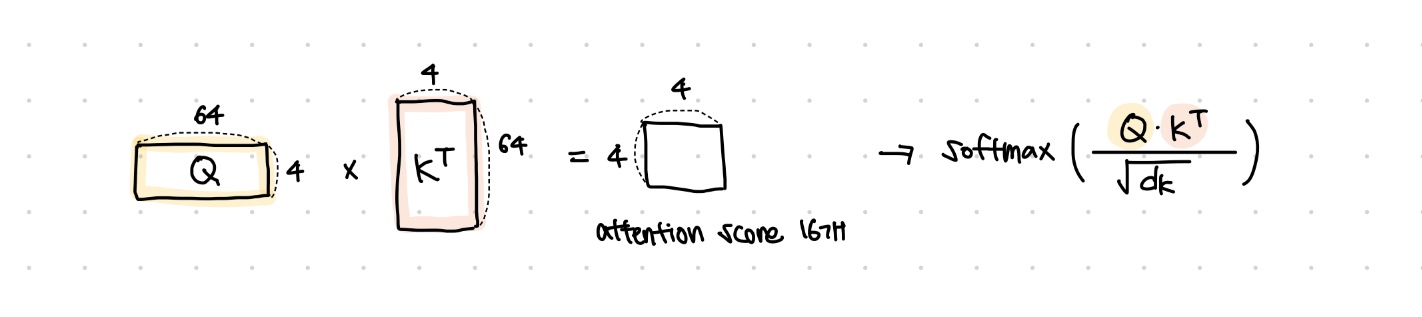
③ 확률값에 Value 벡터를 곱하여 합함 : 가중합 Attention Value 행렬 연산
- 각 Q_i에 K_1, K_2, ... , K_4을 곱해 구한 attention score에 각각 V_1, ... , V_4(64차원)를 곱하여 합한다.
- SUM(K_j * V_j) (j = 1,2,3,4) = Q_i에 대한 attention 벡터 (최종 : 64차원)

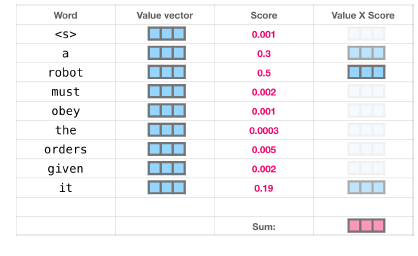
중요한건, 위와 같이 행렬 연산로 input sequence의 모든 단어에 대한 self attention 연산이 동시에 가능하다는 것이다.
병렬 연산이 가능 = 효율적인 연산 가능
■ Multi-Head Attention?
위의 encoder self-attention은 input이 512, output이 64차원이었기 때문에 8번의 서로 다른 attention연산을 수행하여
그 결과값을 concat하고, weight matrix(learnable) 곱하여 최종 output이 출력된다.

- 입력값이 들어왔을 때, h개로 구분됨 (h개의 k, q, v) --- (h개의 Scaled Dot-Product Attention)
- 각 attention에 대해서 다른 W_k, W_q, W_v가 학습된다.
- h개의 서로 다른 attention concept을 학습하도록 만들어서, 하나의 Query 토큰에 대해서 구분되고 다양한 특징들을 학습할 수 있게 해줌
- input과 ouput의 차원이 (512)동일하므로, dimension이 감소하지 않음


■ Masked Decoder Self - Attention
Encoder의 self-attention과 완전 동일한 원리인데, 실제로 추론단계에서 현 시점 이후의 단어를 알 수 없으므로
훈련시킬 때도 이후 시점의 토큰들은 마스킹 처리하고 학습시킴을 의미함
"self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections."
■ Encoder - Decoder Attention
"In 'encoder-decoder attention' layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models."
Encoder의 마지막 레이어 (논문 상 6th layer)에서의 output을 Key, Value 벡터로 받아와서
Decoder의 각 레이어마다 self-attention의 output : Query와 어텐션 연산을 해준다. 이것이 인코더-디코더 어텐션이다.

디코더에서 디코딩을 할 때에서는 <EOS>가 나올 때까지 디코딩을 반복한다.
7. Final Layer

디코더의 마지막 레이터 (6th layer)를 나온 결과물은
Linear layer를 거친다.
Linear Layer은 단순 feed forward neural network의 형태로, 디코더의 출력 결과물 (512차원)을 이용하여 단어사전에 있는 모든 단어 (|V|개)에 대한 등장 확률을 산출하기 위해 차원을 맞춰주는 역할을 수행한다.
즉, 여기서 학습되는 가중치 행렬의 shape은 512 x |V| (단어사전의 크기)이다.
위의 vocab size만큼의 logit에 대하여 softmax 함수를 취해주어
최종적으로 단어사전에 있는 각 단어에 대한 출력 확률이 결과물로 나오게 된다.
그 확률들에 대하여 argmax를 취해주면 가장 확률이 높은 단어가 출력된다.
8. 결과 ( Transformer의 성능)
▶ Why Self - Attention
1. Complexity : RNN과 CNN과 비교했을 때 n<d라면 복잡도가 낮아진다.
2. Parallelized : 많은 양의 연산이 병렬로 수행된다. (not sequential)
3. Long-range dependencies : forward / backward 연산을 수행해야 하는 length of path가 짧아진다.
4. attention 결과를 시각화하여 해석가능한 모델을 디자인할 수 있다.

▶ Performance
당대 기계번역 task에서 SOTA(BLEU 스코어) + 효율성도 있음
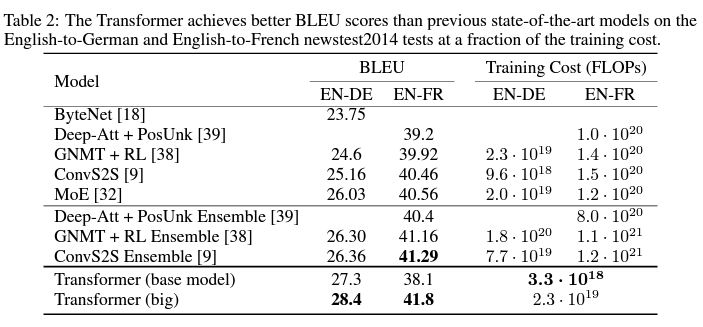
아래는 영어-독어 번역 task에 대하여 multi-attention head 수 (h) , 임베딩 차원 (d_model), FFNN 차원 (d_ff), key/value 벡터 차원 (d_k, d_v)를 달리하면서 BLEU 스코어가 어떻게 변하는지 실험한 결과이다.
노란색 형광펜 부분을 보면 Head 수, d_model, d_ff만 각각 2배로 키웠을 때 성능이 향상됨을 확인할 수 있다.

'Study > 자연어처리' 카테고리의 다른 글
| [cs224n] Lecture 9 - Pretraining (2) (1) | 2024.05.04 |
|---|---|
| [cs224n] Lecture 9 - Pretraining (1) (0) | 2024.04.22 |
| Attention & Transformer (1) (1) | 2024.04.10 |
| Text generation & Machine Reading Comprehension (0) | 2024.04.09 |
| Text Classification (+Benchmark & Evaluation) (1) | 2024.03.24 |