
출처:
cs224n lec.9 : pretraining
- https://web.stanford.edu/class/cs224n/index.html#schedule
- https://www.youtube.com/watch?v=DGfCRXuNA2w&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=9
학교 자연어처리 수업 : Language Model
- https://jalammar.github.io/illustrated-bert/
본문은 Language Modeling / Pretraining의 개념과
논문 : 'Improving Language Understanding by Generative Pre-Training' (GPT-1)
논문 : 'Language Models are Unsupervised Multitask Learners' (GPT-2) 의 내용을 담고 있습니다
워드 임베딩을 하는 방법에는 2가지가 있다.
1) 임베딩 레이어를 랜덤 초기화하여 모델 아키텍쳐와 함께 학습시키는 방법
2) word2vec, glove와 같은 사전 학습된 임베딩 벡터를 가져와서 이용하는 방법
위 방법들로 워드 임베딩을 진행하면 모두 하나의 단어에 하나의 벡터값이 맵핑될 것이다.
따라서 문맥을 고려하지 못하여 다의어 또는 동음이의어에 대한 구분이 안된다는 문제점이 발생한다.
이러한 한계는 사전 훈련된 언어 모델 : Pretrained Language Model의 등장으로 극복할 수 있었다.
언어모델을 사전학습 시키는 방법으로
- 많은 web 데이터 소스를 모두 학습시켜 놓을 수 있게 되었다.
- 파라미터 초기화를 랜덤 초기화하여 처음부터 다 학습시키는 기존의 방법에서 벗어남.
- 학습 전에 학습 데이터에 대한 사람의 labeling이 필요하지 않다.
- unsupervised learning으로 글자 생성뿐만 아니라 코드 생성, 함수 생성 등 다양한 도메인으로의 확장이 가능해졌다.
등의 장점이 있다.
사전훈련 이후 원하는 태스크에 맞게 파인튜닝하는 방식이 기존의 랜덤초기화 후 학습 방식보다 더 좋은 성능을 보인다는 연구의 등장으로 nlp 분야에서 주요 트렌드는 pretrained language model을 만들고 이를 특정 태스크에 추가 학습시켜 해당 태스크에서 높은 성능을 얻도록 하는 방법으로 발전했다.
Pretraining through language modeling
https://arxiv.org/pdf/1511.01432.pdf ('Semi-supervised Sequence Learning')
- Train a neural network to perform language modeling on a large amount of text.
- Save the network parameters. :: pretrained!
★ Pretraining → and then, Finetuning

일단 많은 학습 데이터를 기반으로 general하게 학습을 시킨다.
이를 통해 언어 모델은 문법적 추론, 상황적 맥락에 의한 추론, ... , 감성분류까지 다양한 task를 알아서 학습하게 된다.
이렇게 pretrained language model을 기반으로 parameter 초기화를 한 후에,
내가 원하는 task에 맞는 labeled train data (아마 그 수가 많지 않을 것)로 학습하는 것이다.
이와 같은 학습 방법으로 학습과정에서 loss를 최소화하는 과정이 더욱 유리해진다.
Pretraining Decoders : GPT
OpenAI 발표 블로그 : https://openai.com/index/language-unsupervised (2018)
'Improving Language Understanding by Generative Pre-Training'
기존 언어 모델이 자연어처리 task를 수행하도록 훈련을 시킬 때 많은 양의 text data로 훈련을 시킬텐데, 당연히 대부분의 텍스트 데이터는 라벨링이 되어있지 않다. 이러한 다량의 Unlabeled Data 리소스를 활용할 수 있는 방법이 없었기 때문에 labeled data에 의존하는 supervised learning, 즉 지도학습으로 훈련됐다.
OpenAI에서는 하나의 모델을 개발하여 대량의 Unlabeled Data에 대해 비지도 방식으로 학습시킨 다음, 다양한 작업에서 우수한 성능을 달성하도록 모델을 미세 조정할 수 있을까?라는 research question으로 연구를 시작했고
연구 결과에 따르면 이 접근 방식이 매우 잘 작동했으며, 동일한 핵심 모델을 최소한의 조정만으로 매우 다양한 작업에 맞게 미세 조정할 수 있다고 발표했다.
논문 제목 그대로 Generative Pre-Training 방법으로 Language Model을 개발하여 Improving Language Understanding에 성공한 것이다.
★ Pre-Training : Language Modeling (Unsupervised)
앞의 글에서 나온 트랜스포머 아케텍처에 : transformers 앞서 언급한 pretrain-finetuning으로 task를 잘 수행할 수 있다는 training에 대한 아이디어 : unsupervised pre-training 을 합쳐 현재 GPT-1이라고 불리는 모델을 만들어 사전훈련을 시켰다. 사용 데이터는 unlabeled data source로서 BooksCorpus (책 7,000권)를 활용했다.
다양하고, 다량의 데이터를 이용한 사전학습을 통해 모델은 언어의 다양한 문맥, 언어구조, 언어패턴에 대한 이해가 높아질 수 있었다.
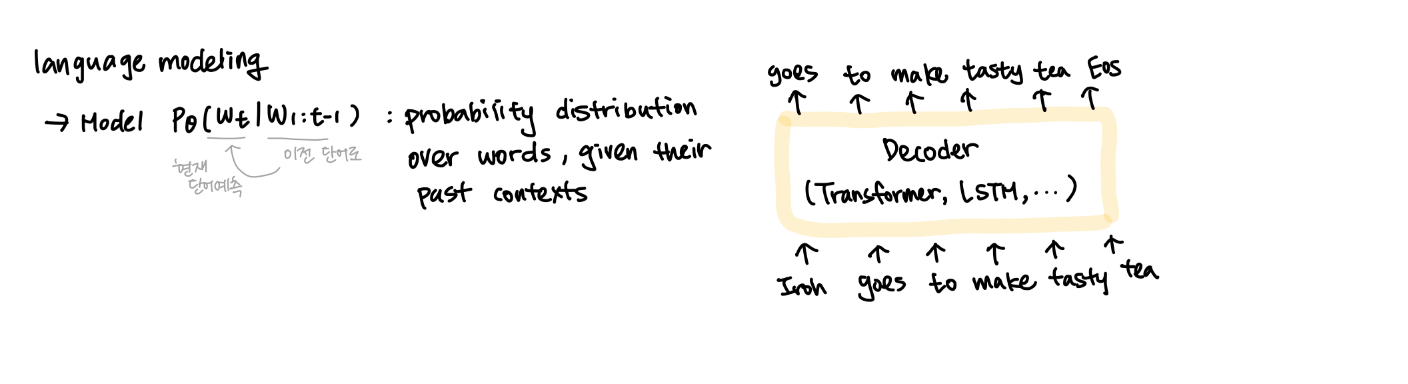
Decoder 사전훈련은 기존의 language modeling과 유사하다.
Language model의 개념 그대로 주어진 input에 대하여 그 다음에 나올 단어에 대한 확률을 예측하는 것이기 때문.
아래 수식에서는 i번째 단어;u_i가 전 k(context window size)개의 단어들이 있을 때 등장할 조건부 확률

따라서 GPT는 아래와 같은 Decoder-only 구조로 pretrained된 uni-directional 모델이다.
트랜스포머의 아키텍처를 활용한다고 했는데, 트랜스포머에서 디코더 부분만 떼어다가 연결시킨 것이다.
그렇기에 디코더에서 인코더의 마지막 head의 output을 key와 value로 받는 encoder-decoder self attention 부분 또한 제거된 형태이다.

- 12개의 decoder block을 쌓아올리고, decoder의 마지막 block에 FFNN+Softmax를 연결
- 따라서 vocab에 있는 모든 단어에 대한 등장 확률로 최종 output이 결정
- (참고 : self attention head dimension = 768, ffnn dimension = 3072)


★ Fine-Tuning : Transfer Learning to Downstream Tasks (Supervised)
사전학습시 훈련된 파라미터 theta로 초기 파라미터를 초기화시킨 후, 이제서야 Labeled Data (적은 양이어도 괜찮음)으로 원하는 Natural Language Understanding **specific** task에 맞게 Fine-Tuning을 시킨다.
이전에 발표된 모델에서 LSTM Language model / ELMo가 보여줬던 가능성처럼, Transformer 기반으로 Pretrained 된 상태의 weight로 초기값을 정해준 다음에 미세조정 훈련을 시작하니, GPT는 적은 양의 데이터로도 지도학습이 가능함과 동시에 문맥을 더 잘 이해하는 언어모델이 되었음을 보여주었다.

앞서 pre-train 단계에서 수식(1)을 최대로 하기 위해 학습되었던 파라미터로 초기화 후, labeled dataset를 가져와서 기존의 architecture의 마지막에 linear output layer 하나를 추가하고 최적의 W_y를 구하도록 훈련됨.식 (4)의 우도함수를 최대화하도록.

참고로 GPT-1은 GLUE 벤치마크의 태스크들을 포함한 다양한 TASK들을 해결하도록 Fine-tuned 된 후 그 성능이 측정되는데, 각 태스크의 특성에 맞도록 input의 조작된다.
예를 들어 전제와 가설의 관계를 알아내는 textual entailment 태스크의 경우 두 문장 사이에 delimiter token($)을 넣는다던가, qa 및 commonsense reasoning 태스크의 경우 passage+question과 answer 사이에 delimiter token을 삽입하는 등의 처리가 있겠다.
해당 프로세스는 아래 그림과 같다.

★ Experiments & Results


(1) Task별 성능
- Textual Entailment : (SNLI / MNLI-M / MNLI-MM / SciTail / QNLI / RTE) 에서 RTE 제외 SOTA
- Similarity : (STS-B / QQP / MRPC )에서 MRPC 제외 SOTA
- Question Answering & Commonsense Reasoning : (RACE / ROCStories / COPA) 에서 모두 SOTA
- Classification : (SST-2 / CoLA)에서 모두 SST-2 제외 SOTA
- GLUE 벤치마크 평균 SOTA
(2) Transfer에 사용한 Layer 개수에 따른 성능
- Impact of number of layers transferred 관찰
- Pretrained layer를 많이 이용할수록 task의 성능이 향상함을 보여줌
(3) Pre-training의 효과
- 언어모델의 Pre-training 업데이트 수에 따른 zero-shot performance 그래프를 그려보면 우상향
- language model pre-training of transformers is effective!
- generative model well learned to perform many of the tasks we evaluate on
- LSTM 모델에 비해 언어 모델링 능력의 향상을 보여주었고, Transformer을 이용하였기에 더 attentional memory가 가능해짐
★ Ablation Study

관측 요소 : auxiliary objective 여부 / Transformer 여부 / pre-training 여부
1. full model with auxiliary LM objective during fine-tuning : NLI 추론 태스크랑 QQP 같은 large dataset에 한해 더 좋은 성능 보임
2. Transformer가 LSTM보다 항상 더 좋은 성능 보임
3. Pre-training을 적용했을 때 항상 더 좋은 성능 보임
GPT-2
OpenAI 발표 블로그 : https://openai.com/index/better-language-models (2019)
'Language Models are Unsupervised Multitask Learners'
앞서 OpenAI는 일관된 텍스트 단락을 생성하고, 여러 언어 모델링 벤치마크에서 최첨단 성능을 달성하며, task-specific training 없이도 독해, 기계 번역, 질문 답변, 요약 등을 수행하는 large-scale unsupervised language model 을 훈련시켰다. (2018)
이번에는 GPT 후속모델로 GPT-2로 40GB의 인터넷 텍스트 데이터로 다음 단어를 예측하도록 훈련시킨 모델이 나왔다. (기술의 악의적 적용 우려로 모델 공개 안함)
GPT-2는 8백만 개의 웹 페이지로 구성된 dataset으로 학습된 1.5B parameter의 transformer기반 언어 모델이다. GPT-2는 텍스트 내에서 이전의 단어들이 주어졌을 때 다음 단어를 예측하는 목표로 학습된다. 즉, 그냥 GPT-2는 GPT에서 10배 이상의 데이터로 훈련시킨 10배 이상의 파라미터를 가지도록 확장 ver. 이라고 보면 된다. GPT-2로 fine-tuning 없이 zero-shot으로 낸 downstream task의 성능은 충분한 데이터와 컴퓨팅 리소스만 있다면 unsupervised pre-training의 이점을 이용할 수 있음을 시사한다.

▶ 모델 훈련 목표 : 단순히 language modeling에서 P(output | input) 이 아닌, P(output | input, task)를 objective로 둠
▶ 모델 훈련에 사용한 데이터 셋 : 레딧 링크를 웹 크롤링 - "WordText" 데이터셋이라고 부름
[ GPT2 Model ]
(1) Input 표현에 대하여
language modeling은 결국 각 단어에 대한 생성 확률을 예측해내는 것인데, 현재 LM은 전처리 과정을 통해 모델링이 가능한 string을 제한한다. 현재 (자주) 사용되는 byte-level LMs 은 큰 데이터셋에 대하여 word-level LMs에 비해 성능이 좋지 않다. 이는 본 논문에서의 실험을 위한 데이터셋인 Web Text 을 이용했을 때도 확인된 바이다.
따라서 여기서는 "Byte Pair Encoding (BPE)"를 도입한다.
BPE : a practical middle ground between character and word level language modeling which effectively interpolates between word level inputs for frequent symbol sequences and character level inputs for infrequent symbol sequences.
유니코드를 기반으로 하되, 모든 word level을 일대일대응으로 표현하려면 vocabulary size가 지나치게 커지기 때문에 byte-level를 적용하면 vocab size가 256으로 제한된다. 이러한 방법 (자세한 구현 방법은 생략, 위 허깅페이스 사이트 링크 참조) 을 이용하면 어떠한 Unicode string에 대해서도 생성 확률을 계산할 수 있게 되고, 이는 훈련시킨 Language Model을 어떠한 데이터셋에 대해서도 평가가 가능하도록 해준다는 장점이 있다.
(2) Model Architecture
GPT-1 구조와 거의 유사, Normalization layer의 위치, vocab size, token size의 확장등이 작은 차이이다.

모델 사이즈 배리에이션은 위 표와 같이 4가지이며, 첫번째는 GPT 사이즈, 두번째는 BERT 사이즈와 동일하다. 마지막 모델 (가장 큰 모델)이 우리가 부르는 'gpt-2'이다.
[ Experiments and Results ]
Language Modeling

- zero-shot 셋팅에서 7/8 sota
[ Generalization vs Memorization ]
데이터셋의 크기가 커지면서 데이터가 중복되는 경우 발생 , 따라서 test data가 얼마나 training data안에 포함되어 있는지 살펴봄
이렇게 highly similar text가 performance에 미치는 영향을 파악하는 것을 중요한 연구 주제임.
8-gram token (모두 소문자화) 필터링을 통해서 false positive rate (같은데 같지 않다고 판단하는 경우)를 낮춤

그 결과 매우 적은 비율로 워딩이 overlapped 되어 있음을 관측할 수 있었음
이 외에도 WebText LM이 기억력에 의존해서 성능을 내는 것인지 판별하는 다른 방법으로는 train-test dataset에 대한 각각의 성능을 비교해보는 것인데, 그 결과 성능이 train set이나 test set이나 거의 비슷하고, model size의 증가에 따라 성능이 향상하는 것으로 보아 GPT-2 모델이 WebText 데이터로 과소적합 됐으면 과소적합 되었지, 오버피팅 되지는 않았을 것이라고 말한다.

'Study > 자연어처리' 카테고리의 다른 글
| Language Models are Few-Shot Learners (0) | 2024.05.20 |
|---|---|
| [cs224n] Lecture 9 - Pretraining (2) (1) | 2024.05.04 |
| Attention & Transformer (2) (1) | 2024.04.10 |
| Attention & Transformer (1) (1) | 2024.04.10 |
| Text generation & Machine Reading Comprehension (0) | 2024.04.09 |