
저번글 이어서.................
2024.04.22 - [Study/자연어처리] - [cs224n] Lecture 9 - Pretraining (1)
출처:
cs224n lec.9 : pretraining
- https://web.stanford.edu/class/cs224n/index.html#schedule
- https://www.youtube.com/watch?v=DGfCRXuNA2w&list=PLoROMvodv4rMFqRtEuo6SGjY4XbRIVRd4&index=9
학교 자연어처리 수업 : Language Model
- https://jalammar.github.io/illustrated-bert/
Pretraining Encoders : BERT
앞서 language modeling에 대한 transformer의 decoder 구조만 활용한 generative pre-training을 살펴보았다.
인코더의 경우 양방향을 모두 고려한 언어 모델을 만든다고 생각할 때,
'양방향을 본다'는 것은 내가 다음 시점의 단어를 예측해야 하는데 이를 input으로 받는다.. 는 모순이 생기게 된다.
따라서 제안된 방식이 Masked Language Modeling이다.
MLM은 문장의 일부 단어를 [MASK] 토큰으로 대체하고 대체된 단어들을 예측하는 언어 모델링 기법이다.
MLM 방법은 BERT : Bidirectional Encoder Representations from Transformers에서 제안되었다.
위에서 설명한 것과 같이, 직관적으로 양방향 문맥을 보는 것이 언어모델링의 성능을 높일 수 있음(단어 의미를 파악하는데 매우 중요)에 불구하고 기존의 Left - to - right 방식의 언어 모델링은 문장 시작부터 순차적으로 예측한다는 점에서 일방향(unidirectional)이기 때문이다.
(left-context-only version is referred to as a “Transformer decoder” since it can be used for text generation)
즉 BERT의 핵심을 한 줄 요약하면
"트랜스포머 인코더 기반의 Fine-tuning approach로, 양방향 문맥(bidirectional context)를 고려하여 학습함"이라고 할 수 있다.
이 방법으로 sentence-level / token-level의 다양한 NLU 태스크에서 SOTA 성능을 달성했다.
★ BERT : Pre-training
BERT 모델이 사전 훈련된 방법은 크게 2가지 TASK : Masked LM & NSP를 기반으로 한다.

Task #1: Masked LM
BERT : Bidirectional Encoder Representations from Transformers 를 maked LM 방법으로의 훈련과정을 간략히 설명하면 아래와 같다.
먼저, 문장 토큰의 15%를 랜덤으로 선택한다. 이 가운데
- 80%는 기존 input → [MASK]로 대체
- 10%는 기존 input → 랜덤 다른 token으로 대체
- 10%는 기존 input → (그대로 둔다)

모델이 예측하도록 학습하는 15%의 모든 "masked" 단어들을 [MASK]로 대체하지 않는 이유는
실제로 fine-tuning 단계에서는 [MASK] 라는 special token이 등장하지 않을 것이기 때문이다. 따라서 pretraining 단계와 finetuning 단계의 간극을 줄이기 위해서 위와 같이 Replaced/Not Replaced/Masked의 비율을 1:1:8로 두고 기존의 토큰을 cross-entropy의 최소화 방향으로 예측하도록 훈련시키는 것이다.
Task #2: Next Sentence Prediction (NSP)
QA나 Paraphrase detection, NLI와 같은 NLP downstream task는 2개의 문장 간의 관계에 대한 이해를 기반으로 한다. 이러한 이해는 위와 같은 language modeling 방식으로 이해되기 쉽지 않다. 따라서 문장 간 관계를 이해시키는 모델로 훈련시키기 위해서, 'next sentence prediction' task로 사전훈련을 시킨다.
사전 훈련시킬 때 데이터로 문장 A와 B가 있다고 하면 50%는 B가 정말로 A 다음 문장으로 올 수 있는 경우로 하고(labeled as IsNext), 나머지 50%의 경우로는 corpus로부터 랜덤한 문장으로 나열되었다.

위 그림을 참고하자면 hidden vector output : 'C'는 NSP를 위해 사용된다.
MLM과 NSP는 함께 훈련되는 것이고, [CLS]가 NSP 태스크를 위해 pre-train되는 와중에 다른 token representations들은 MLM 태스크를 위해 훈련되는 것이라고 해석할 수 있다.

★ BERT : Model Architecture
논문에서 제시하는 BERT 모델의 두 가지 사이즈는 :
- BERT BASE : OpenAI Transformer와 비슷한 사이즈로, 같은 사이즈일 때 성능 차이를 비교하기 위해 만들어진 베이스 모델
- BERT LARGE : 논문에서 제시하는 최고 성능을 달성한 모델
간단하게는, 트랜스포머 인코더 레이어를 12개 쌓았는가, 24개 쌓았는가의 차이이다.

★ BERT : Model I/O
Input에 있어서는 기존의 Transformers Encoder와 큰 차이가 없다. 논문에서는 토큰의 임베딩을 위해서 vocab size가 30,000 토큰인 WordPiece embeddings (Wu et al., 2016) 을 사용한다.
다만, 첫 입력 토큰으로는 반드시 [CLS]라는 special token을 받는다.
각각의 입력 토큰들은 self attention - ffnn 수행 후, 다음 인코더 레이어로 전달되는 과정이 반복된다.

각 포지션에 대해서 output은 hidden_size 크기의 벡터이다. (BERT BASE의 경우 d_h = 768)
pre-trained BERT model을 sentence classification의 용도로 fine-tuning하는 경우에는 첫번째 [CLS] token에 대응하는 hidden vector가 입력 sequence에 대한 정보를 압축한 벡터로 사용된다.

pretrained BERT가 수행할 task의 input으로 두 개의 문장이 입력될 수도 있기 때문에 두 문장을 모델 입장에서 하나의 input sequence로 받는 방법도 필요했다. 이를 위해서 (1) : special token [SEP]으로 두 문장을 구분지었다. (2) : 기존의 Token Embedding에 문장을 구분짓는 역할을 하는 Segment Embedding (E_A or E_B)을 추가로 더해주었다.
★ BERT : Fine-Tuning
사전 훈련을 한 번 완료하면, 그 모델을 기반으로 Task - specific 하게 여러 번 fine-tuning이 가능해진다.
각각의 task에 대해서 input과 output을 모델에 넣어 end to end로 모든 파라미터 (사전학습된)를 파인튜닝했다.
single text, text pairs 등 input type과 관계없이 Transformer 아키텍쳐의 Encoder 부분의 self - attention mechanism을 활용해서 BERT는 다양한 downstream task를 위한 fine-tuning이 가능해졌다. text pairs가 input으로 들어가는 경우, 선행연구에서는 양방향 cross attention을 적용하기 전에 각각의 문장을 독립적으로 인코딩했었다.
하지만 BERT는 두 문장을 붙여서 text pair를 한 번에 인코딩하고 self-attention을 수행하는 방식으로 문장 간의 양방향 cross attention이 가능하도록 디자인되었다.
Sentence-level tasks, 예를 들어 NLI 태스크나 Single sentence에 대한 분류 task (SST-2/CoLA) 등은 아래와 같이 파인튜닝이 가능하다.

text classification task에 대한 예시를 들어보면 아래 그림과 같다.
기존의 사전학습된 모델 마지막에 single-layer neural network를 분류기로 추가해서 input에 대한 output(label: Spam or Not Spam)이 출력되도록 task specific하게 fine-tuning되는 것이다.

Token-level tasks, 예를 들어 QA 태스크(SQuAD : 답변의 start/end span 예측) 나 Single sentence에 대한 태깅 task (NER이나 Pos Tagging 등)도 거의 비슷하게 아래와 같은 구조로 파인튜닝이 가능하다.

attention을 수행하고 나오는 hidden representation들에 대해 상단에 linear classifier을 갖다 붙이면 됨
얘는 토큰마다 분류기를 붙여야 하므로 토큰 수 * h _dim * class 수 만큼의 새로운 parameter들을 fine-tuning 과정에서 학습하게 된다.
★ Performance
뭐, 예상대로 훌륭하다.
(1) GLUE tasks

(2) SQuaAD
- SQuAD2.0 task extends the SQuAD1.1 problem definition by allowing for the possibility that no short answer exists in the provided paragraph,making the problem more realistic
- 기존 SQuAD v1.1 BERT model에서 확장 : treat questions that do not have an answer as having an answer span with start and end at the [CLS] token
(3) SWAD
- The Situations With Adversarial Generations (SWAG) dataset contains 113k sentence- pair completion examples that evaluate grounded commonsense inference (Zellersetal.,2018).
- Given a sentence,the task is to choose the most plausible continuation among four choices.



★ Ablation Study
(1) Model Sizes

모델을 충분한 양의 데이터를 가지고 사전학습이 되었음을 전제로 할 때, 모델의 크기가 커질수록 확실히 작은 task에 적용할 때 (fine-tuning을 했을 때) 좋은 성능을 보임을 밝혔다.
특히 MRPC 데이터셋과 같이 downstream task를 수행하는 데이터셋의 크기가 작고 사전 훈련 태스크와 상당이 다르더라도 충분히 좋은 선능을 달성함을 보였다.
(2) Training Efficiency


No NSP : MLM 기반으로 훈련된 bidirectional model, 하지만 NSP 태스크로는 훈련되지 않음
LTR & No NSP : MLM 없이, Left-to-Right (LTR) 기반 훈련, 그리고 NSP 태스크로도 훈련되지 않음
- 우측 표에서 BERT (BASE)와 No NSP를 비교했을 때 NSP 태스크 기반 훈련으로 약간의 성능 향상이 있었음을 보임
- No NSP와 LTR & No NSP의 비교로 양방향성을 적용한 MLM 훈련으로 큰 성능 향상이 있었음을 보임, 특히 QA 태스크인 SQuAD 데이터셋에서 큰 성능 향상을 보여줌
(3) Feature-based Approach with BERT
위에서 제시된 BERT 모델의 결과들은 모두 (1) pre-training model (2) simple classification layer를 추가하여 각 downstream task에 대한 fine-tuning을 진행하는 'fine-tuning approach'를 기반으로 하였다.
하지만 pretrained model에서 feature들을 추출해내는 feature-based approach에도 장점이 있다.
(cf. pre-trained language representations을 downstream task에 적용하는 전략에는 크게 두 가지가 있는데, 그 두 가지가 feature-based / fine-tuning이다. ELMo와 같은 feature-based approach는 task-specific respresentation을 사용한다.)
( feature-base approach의 장점은 transformer의 encoder만 사용하는 bert architecture의 특성상 이러한 구조가 task를 해석하고 문제를 해결하는데 부족할 수 있다는건데, 이런 경우에 task-specific representation이 추가되어 task 성능에 도움이 되고 연산적으로도 도움이 될 수 있다는 것이다.)
본 논문에서는 BERT 구조에서 두 방법론을 비교하고자 NER task에 fine-tuning approach와 feature-based approach 모두 적용하여 실험을 진행한 결과는 아래와 같았다.
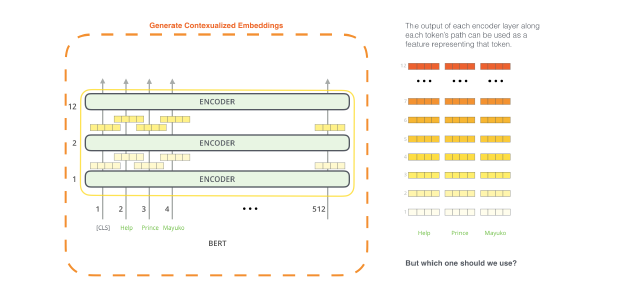

fine-tuning approach로 모든 사전훈련된 파라미터들을 조정하는 것이 가장 성능이 좋았지만, 특히 concat last 4 hidden layers의 경우에 fine-tuning 의 경우와 거의 유사한 성능을 내어 BERT가 두 가지 방식에서 모두 좋은 성능을 낸다는 사실을 확인할 수 있었다.
이후 BERT 계열 발전
- RoBERTa : nsp 훈련 없앰, 훨씬 성능 좋아짐
- ALBERT
- ELECTRA
- Multilingual BERT
- DistillBERT
'Study > 자연어처리' 카테고리의 다른 글
| Chain of Thought Prompting (0) | 2024.05.27 |
|---|---|
| Language Models are Few-Shot Learners (0) | 2024.05.20 |
| [cs224n] Lecture 9 - Pretraining (1) (0) | 2024.04.22 |
| Attention & Transformer (2) (1) | 2024.04.10 |
| Attention & Transformer (1) (1) | 2024.04.10 |