
https://arxiv.org/pdf/2005.14165
OpenAI에서 발표한 GPT-1, GPT-2 논문에 이어 GPT-3 모델을 발표한 논문이다.
"Language Models are Few-Shot Learners" (2020)
Pretraining-Finetuning 훈련 프로세스를 통해 다량의 unlabeled data로 비지도 학습 후 task-specific하게 지도학습을 하는 모델이 소개되고 많은 NLP tasks를 잘 처리할 수 있게 되었지만, 여전히 finetuning 과정에서 다량의 labeled 데이터가 필요한 것은 사실이다.
그래서, 사람처럼 예시 / 지시사항을 통해 새로운 language task를 수행할 수 있게 할 수 없을까? 라는 research question으로부터 연구가 시작된다. 논문에서는 175B 짜리 autoregressive language model을 만들어서 별도의 파인튜닝 없이 few-shot만으로도 다양한 task에서 훌륭한 성능을 냄을 확인했다.
Introduction
◈ Pretrained Transformers + Fine-tuning 구조의 문제점에 대하여
pre-trained transformer language model을 직접 fine-tuning하여 task-specific한 nlp tasks을 해결할 수 있도록 하는 추세였다. 하지만 이 접근법에 있어서 한계는 모델 구조가 어떤 task에도 적용할 수 있도록 훈련되었지만 여전히 fine-tuning을 위해서는 특정 task에 맞는 데이터셋과 별도의 미세조정 과정이 반드시 필요하다는 것이었다.
(1) 효율성 (Efficiency) 측면 : 원하는 specific task에 맞는 데이터셋을 직접 대용량 구축해야 한다는 문제.
(2) 효과성 (Accuracy) 측면 : 학습 시기에 배운 i/o간의 특정 관계에 대해 overfitting 되는 경우, 새로운 test data에 대해 inference를 수행할 때 잘못된 추론 결과를 내놓는 경우가 발생함. 따라서 benchmark에서 높은 성능을 달성하더라도 실제 task에 적용될 때 좋은 성능을 발휘하지 못할 수 있음. (poor generalization)
(3) 꼭 훈련(파인튜닝)이 필요한가..? : 여전히 '사람'처럼 task에 대한 결과를 바로 추론하는 것이 아닌, '(labeled)데이터'를 이용한 지도학습이 필요함.
◈ Solutions : Scaling / In-context Learning
GPT-3 (본 논문) 이전에도 위의 pretrain-finetuning paradigm에 대한 문제가 제기되어 왔었고, 이에 대한 해결책으로 크게 2가지가 제안된다.
첫 번째는 'Scaling'이다. 말 그대로 모델 사이즈 (파라미터 수)를 늘리는 것이다.
OpenAI에서는 모델의 크기와 성능은 비례 관계를 가짐을 확인했다.
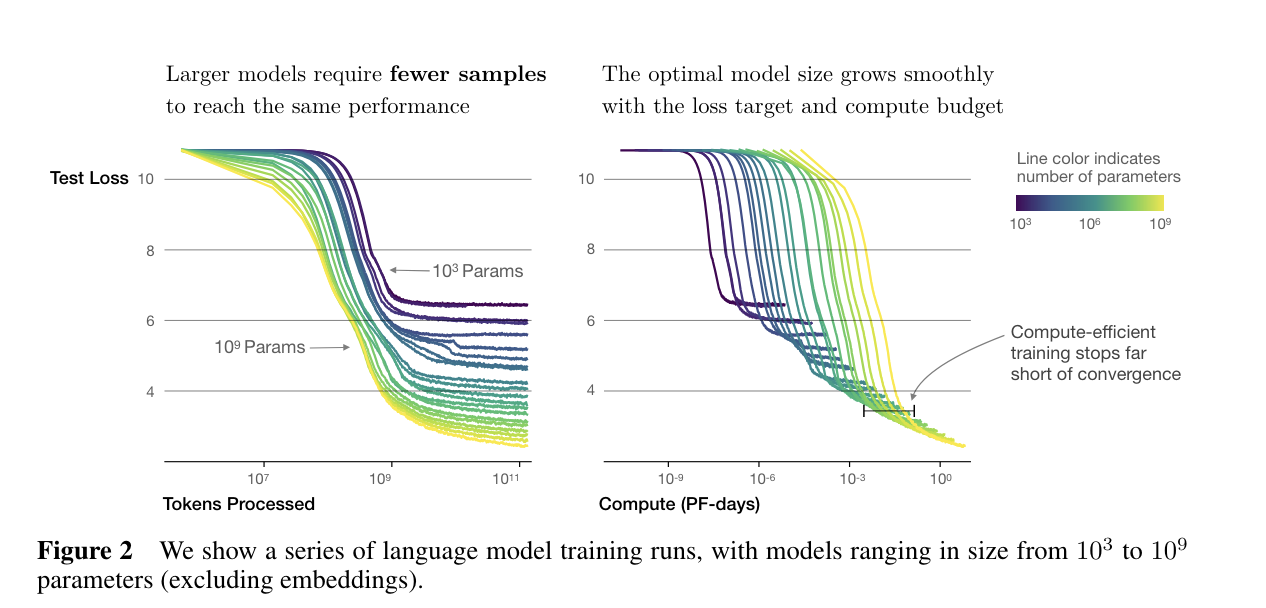
두 번째는 'In-context learning' or 'meta-learning'이다.
모델은 다양한 데이터셋을 기반으로 사전 훈련 과정에서 다양한 nlp task 수행 능력을 학습하고 → 해당 능력을 추론 시간에 활용하여 원하는 특정 task를 빠르게 인식하고 적용할 수 있도록 한다. (Figure 1.1) 이는 'in-context learning'이라고도 부르는데, pretrained model의 input (예를 들어 자연어 명령)을 task specification으로 이용하는 것이다.
(이러한 방법은 gpt2 논문에서도 실험됨, 하지만 전반적으로 성능이 뛰어나지 못했음 / 파라미터 수를 늘렸을 때 성능 향상에 대한 가능성을 확인했음)

이 논문에서는 in-context learning이 model의 fine-tuning 과정 없이도 (파라미터 업데이트 없음) task에서 높은 성능을 낼 수 있다는 가설을 확인하기 위해서 175B짜리 언어모델 : GPT-3 모델을 이용하여 in-context learning 능력을 측정한다.
3가지 conditions : (a) "few-shot learning" / (b) "one-shot learning" / (c) "zero-shot" learning 아래에 GPT-3를 다양한 nlp tasks에 대해 평가를 진행한다.

실험 결과,
(1) natural language task description 을 추가했을 때,
(2) example의 수가 증가할수록,
모델의 성능이 향상함을 확인할 수 있다.
또한 Few-shot leaning 환경에서 model size가 커질수록 (1.3B < 13B < 175B) 성능이 향상함을 확인할 수 있다. (특히 175B 모델의 경우 추론 정확도 그래프가 매우 빠르게 증가함)
한 가지 추가하자면, 위 그래프를 보면 example 수가 적을 때 (zero-shot, one-shot, few(small k)-shot)는 prompt가 있고 없고의 성능 차이가 유의미한데, example 수가 많을 때는 그 차이가 거의 없다는 것이다.
저자는 원래의 방식 (parameter optimization, update 방식)이 아닌, in-context learning을 통한 성능임을 강조한다.
GPT-3 Approach
- pre-training 방식은 GPT-2 논문과 동일
사전에 제시된 scaling approach + in-context learning approach를 모두 적용하여 성능을 내려고 함!

→ FT : updating the weights of a pre-trained model by training on a supervised dataset specific to the desired task
이 논문에서는 GPT-3에 적용하지 않음
→ FS : the model is given a few demonstrations of the task at inference time, but no weight updates are allowed
위 그림에서는 영어를 불어로 번역한 K개의 예시들 (context:영어 + desired completion: 불어 번역본)이 주어짐
SOTA fine-tuned model에 비해서는 아직 성능이 낮음
→ 1S : same as few-shot, except that only one demonstration is allowed (in addition to a natural language description of the task)
→ 0S : same as one-shot, except that no demonstrations are allowed (only given a natural language instruction describing the task)
◈ Model and Architectures
- GPT-2 구조를 그대로 사용, 차이는 'using the alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer'

- 모델 사이즈는 위의 표와 같이 8가지로 변형, 모든 모델에 대하여 context window size는 2048 토큰으로 통일함,
- 이 ctx window 사이즈 (Max token 수)를 GPT-2에 비해 크게 하여 few-shot이 가능하도록 만들었다.
◈ Training & Evaluation
→ Dataset
Common Crawl dataset을 이용하되, 퀄리티 개선 절차 (정제)를 거침
잘 알려져 있는 / 고 퀄리티의 데이터셋과의 유사성을 고려하여 필터링
Common Crawl 데이터 외에도 high quality data (Webtext2)등을 추가함
모든 downstream task 데이터셋의 dev sets을 학습데이터에 포함하지 않음을 목표로 함 (하지만 추후에 일부가 포함되어 있었음이 확인됨)
→ Training Process
applied large batch size & smaller learning rate
→ Evaluation
few-shot learning의 경우 context의 수 (K)를 달리 해가면서 실험을 진행했는데 보통 모델들은 10~100개의 context를 input으로 받을 수 있었다.
- 여러 선택지들 사이에 하나의 정답을 선택하는 task / 이중 분류하는 task / free-form completion task 등 task의 종류에 따라 평가 방법을 달리함
Experiment & Results
위에서 제시된 사이즈별 8개의 GPT-3 모델들이 모두 9 카테고리의 nlu task에 대해 평가가 진행되었다.
◈ Traditional Language Modeling
[Language Modeling]
- PTB (metric : zero-shot perplexity )
- 기존 zero-shot SOTA 성능 : 35.8에 비해 20.5로 관측, 새로운 성능 달성
[Cloze & Completion]

- LAMBADA (metric : Accuracy)
: tests the modeling of long-range dependency in text, predicting the last word
: GPT-3는 few-shot setting에서 86.4%의 정확도를 달성, 기존 SOTA에 비해 18% 향상
- HellaSwag (metric : Accuracy)
: tests if the model picks the best ending to story
: GPT-3 기준 78.9%(0-shot) / 78.1%(1-shot) / 79.3%(few-shot), worse than SOTA, 그러나 여기서 SOTA는 fine-tuning된 모델이었기 때문에 fine-tuned vs few-shot 을 비교하면 굉장한 성능임
- StoryCloze (metric : Accuracy)
: choose correct ending sentence for a five-sentence story
: GPT-3 기준 83.2%(0-shot) / 84.7%(1-shot) / 87.7%(few-shot), worse than SOTA, 그러나 여기서 SOTA는 fine-tuned 모델이었기 때문에 fine-tuned vs few-shot 을 비교하면 굉장한 성능임
◈ Closed Book QA
언어 모델이 보조적인 정보의 제공 (conditioning on auxiliary info) 없이 질문에 대한 답을 할 수 있는 능력을 평가하는 task들이다.
3가지 QA 데이터셋 (metric : Exact Match + F1)
- Natural Questions
- Web Questions
- TriviaQA

Trivia QA의 경우 GPT-3 의 one-shot이 open-domain fine-tuning SOTA 성능에 준하였으며, 다른 두 데이터셋에 대해서는 fune-tuning 과정 없이도 거의 SOTA에 가까운 성능을 냈다. 3가지 데이터셋에 대해 모두 모델 사이즈와 성능이 비례함이 확인되어서 모델의 능력 (성능)이 증가한 모델의 파라미터에 담긴 '지식'으로부터 나온다는 아이디어를 낼 수 있었다.
◈ Translation
말 그대로 번역 task (metric : BLEU score)
- training data의 93%가 영어 데이터, 나머지 7%는 다른 언어의 데이터
- 현존하는 NMT frameworks: pre-training on a pair of monolingual datasets with back-translation to bridge the two languages in a controlled way
- BUT GPT-3 learns from a mix of data that is blended in a natural way, combined on a word, sentence, and document level
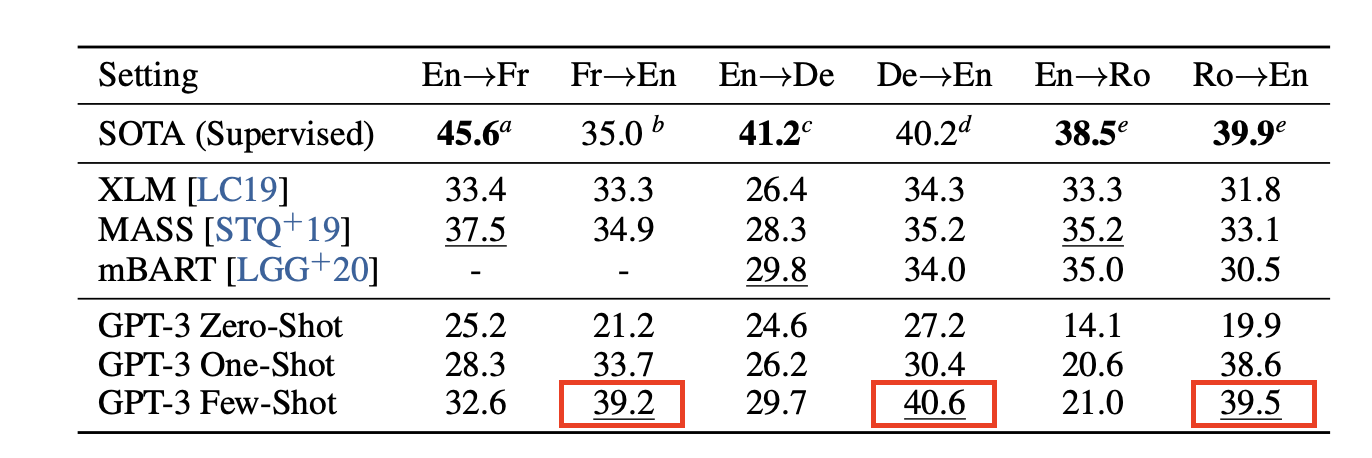
few-shot 번역 성능 (위 표의 6가지 방향성에 대하여)을 실험해보았을 때 모델 크기가 증가할수록 성능이 증가했고, 빨간색 박스의 BLEU score의 경우에 supervised model (SOTA)보다 성능이 높은 것으로 보아 다른 언어를 영어로 번역하는 능력이 더 강함을 확인할 수 있다.
◈ Winograd-Style Tasks
Winograd/WinoGrande Schemas Challenge (metric : Accuracy)
: classical task in NLP that involves determining which word a pronoun refers to, when the pronoun is grammatically ambiguous but semantically unambiguous to a human

◈ Commonsense Reasoning
상식추론을 테스트(metric : accuracy) 하는 태스크로 3가지 데이터셋이 있다 :
- PIQA
- ARC
- OpenBookQA

상식추론의 경우, 해당 태스크를 위한 데이터셋을 만드는데 비용이 많이 들기 때문에, 어떻게 하면 zero-shot으로 좋은 성능을 낼 수 있을지 연구가 많이 되고 있음
* : 29% of PIQA test-set seen at training, clean subset : -13%
◈ Reading Comprehension
기계독해 태스크에 대한 평가 (Metric : F1, RACE는 accuracy)
- CoQA / DROP / QuAC / SQuADv2 / RACE-h / RACE-m

- CoQA 데이터에 대해서는 SOTA보다 살짝 낮은 성능,
- 나머지 데이터셋들은 훨씬 낮은 성능
◈ SuperGLUE

- 또한 성능은 모델 사이즈가 커질수록, context에 포함된 예시의 수가 증가할수록 좋아짐을 확인할 수 있었다.
◈ NLI
두 문장 간의 관계에 대해 이해하는 능력을 테스트하는 태스크
2문장 또는 3문장 사이의 관계에 기반하여 분류하는 문제 (metric : accuracy)

RTE의 경우 SuperGLUE 성능에서 확인 가능 : fine-tuned BERT와는 성능이 비슷하지만 SOTA보다는 낮음
ANLI의 경우 위 그래프에서 확인할 수 있듯이 항상 성능이 매우 안 좋음
◈ Synthetic and Qualitative Tasks
we test GPT-3 on several qualitative tasks, including using new words in a sentence, correcting English grammar, and news article generation -> 정말 다양한 새로운 태스크들을 만들어서 실험 진행
(결과 나열 생략)
Measuring and Preventing Memorization of Benchmarks
Since our training dataset is sourced from the internet, it is possible that our model was trained on some of our benchmark test sets. Accurately detecting test contamination from internet - scale datasets is a new area of research without established best practices.
While it is common practice to train large models without investigating contamination, given the increasing scale of pretraining datasets, we believe this issue is becoming increasingly important to attend to.

'Study > 자연어처리' 카테고리의 다른 글
| SummEval: Re-evaluating Summarization Evaluation (0) | 2024.08.10 |
|---|---|
| Chain of Thought Prompting (0) | 2024.05.27 |
| [cs224n] Lecture 9 - Pretraining (2) (1) | 2024.05.04 |
| [cs224n] Lecture 9 - Pretraining (1) (0) | 2024.04.22 |
| Attention & Transformer (2) (1) | 2024.04.10 |