
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
→ link: https://arxiv.org/abs/2201.11903. (2022)
"chain of thought" 이라는 방법으로 llm이 복잡한 reasoning(추론) tasks 수행 성능을 높이는 것에 대한 논문
NLP 분야에서는 언어모델의 태스크 수행 능력을 scale-up을 통해 향상시키고 있었음.
하지만 이에도 한계가 있었는데..
arithmetic, commonsense, and symbolic reasoning (수식추론, 상식추론, 기호추론)의 문제에서의 성능이 정말 낮다는 것.
reasoning ability를 향상시키기 위한 방법으로 GPT-3 논문에서는 in-context few-shot learning via prompting 을 시도했고 실제로 Question-Answering와 같은 간단한 태스크에서는 해당 방법으로 성능이 향상됐다.
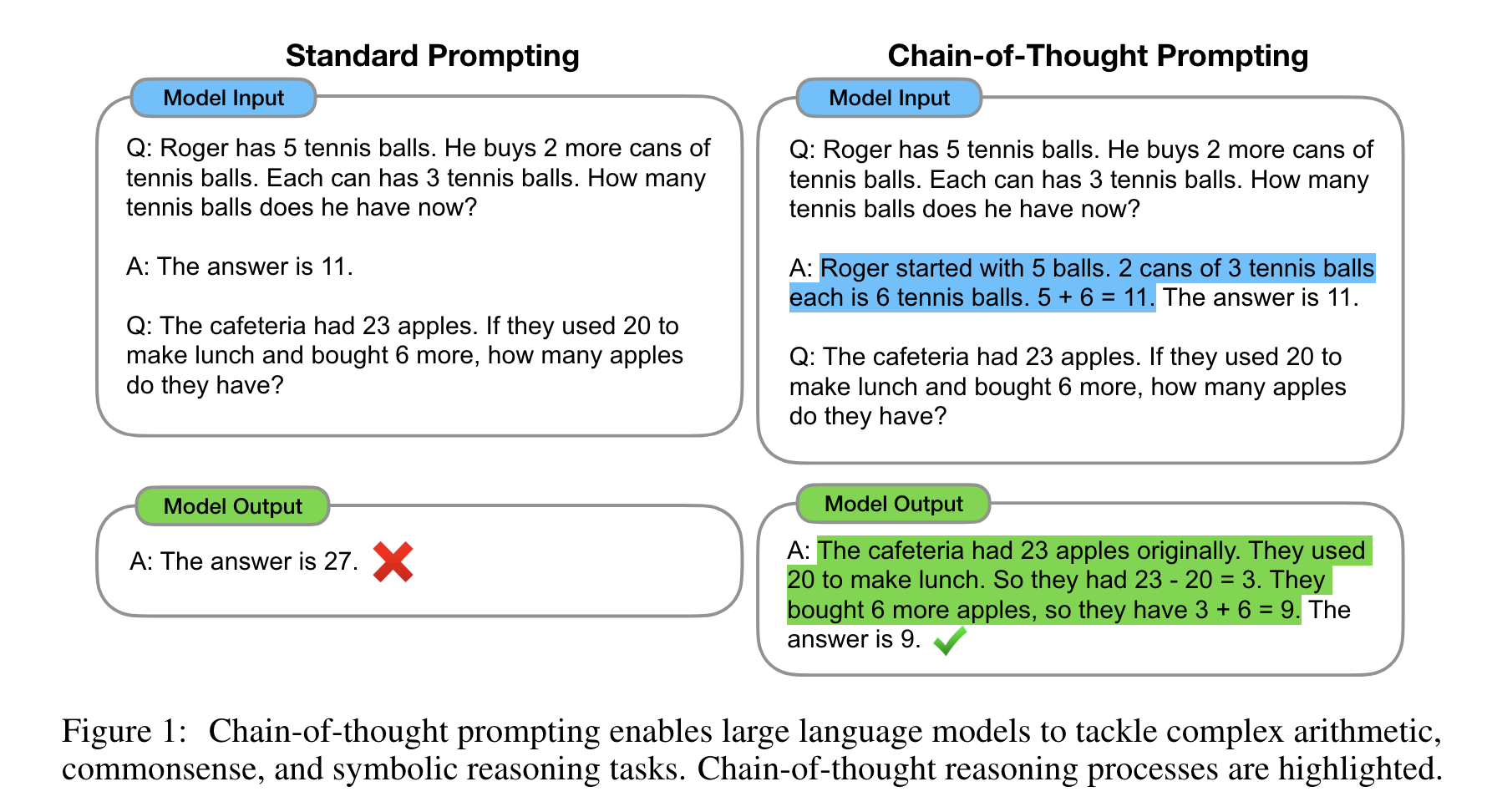
하지만 위 그림 (Figure 1)에서 확인할 수 있듯, 'Standard Prompting' 방법을 통해서는 산수 문제를 푸는데 어려움이 있다는 사실을 확인할 수 있다. 또한, LLM의 scaling에 따라 성능이 향상되지도 않음. 그래서 Figure 1의 우측과 같은 'Chain of Thought Prompting'을 이용하게 됨.
A chain of thought is a series of intermediate natural language reasoning steps that lead to the final output,
and we refer to this approach as chain-of-thought prompting.
Chain-of-thought prompting는 few-shot을 준다는 점이 기존의 prompting과 동일하지만,
"Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5+6=11"이라는 중간과정을 input과 output 사이에 넣어서
Reasoning task에서 더 좋은 성능을 낼 수 있도록 했다.
이렇게 성능이 향상될 수 있는 이유로 논문에서는 4가지 이유를 제시하는데,
첫째 ) 다 단계 문제를 쪼개서 모델이 풀도록 한다는 것,
둘째 ) 모델이 output을 도출하는 과정을 해석가능하도록 해주었다는 것,
셋째 ) 복잡한 문제들, 사람이 자연어를 통해 해결할 수 있는 문제라면 해결이 가능해짐
넷째 ) 큰 llm모델이더라도 단순히 그냥 few-shot만 제공해주면 된다는 것
이 있다.
여기서부터는 그래서 어떻게 'CoT Prompting'이 1. Arithmetic reasoning / 2. Commonsense reasoning / 3. Symbolic reasoning 에서 더 나은 output 출력에 효과를 보이는지 보여준다.
1. Arithmentic Reasoning
● Benchmark : (1) GSM8K, (2) SVAMP, (3)ASDiv, (4) AQuA, (5)MAWPS
● Test Model : (1) GPT-3, (2) LaMDA, (3) PaLM, (4)UL2 20B, (5) Codex
[ Exemplar ]

[ Results ]

1. CoT Prompting은 크기가 작은 모델에서는 오히려 역효과 (100B 정도는 되어야 효과 o)
2. CoT Prompting은 주어진 task가 복잡할 때 더 효과가 좋다 (가장 복잡한 task인 GSM8K의 경우, GPT나 PaLM 가장 큰 모델에서 성능이 확 뜀)
3. GPT-3 175B 모델이나 PaLM 540B 모델에서의 CoT Prompting은 거의 finetuned SOTA에 준하는 성능을 보임
LaMDA 모델로 GSM8K 벤치마크를 테스트 했을 때의 예시를 통해 CoT Prompting을 적용했음에도 불구하고 정답이 틀린 케이스 분석을 한 결과,
46%는 문제 풀이 과정은 옳았으나 연산 실수의 경우 / 54%는 아예 풀이 과정에 오류가 있었다.
프롬프트를 주는 방식에 따라 성능이 달라지지 않을까? 라는 의문이 들 수 있었지만, 다양한 방식의 prompt를 주었음에도 불구하도 chain of thought를 포함한다면 standard prompting 방식보다 항상 성능이 높다는 강건성을 보여주었다.
2. Commonsense Reasoning
● Benchmark : (1) CSQA, (2) StrategyQA, (3)Date, (4) Sports, (5)SayCan
● Test Model : (1) GPT-3, (2) LaMDA, (3) PaLM, (4)UL2 20B, (5) Codex

'Study > 자연어처리' 카테고리의 다른 글
| SummEval: Re-evaluating Summarization Evaluation (0) | 2024.08.10 |
|---|---|
| Language Models are Few-Shot Learners (0) | 2024.05.20 |
| [cs224n] Lecture 9 - Pretraining (2) (1) | 2024.05.04 |
| [cs224n] Lecture 9 - Pretraining (1) (0) | 2024.04.22 |
| Attention & Transformer (2) (1) | 2024.04.10 |